总计 103103 张截图
还有两周就要回学校了……
0x00.前言
最近(8 月份)bilibili 直播区搞了一项活动,名为<title>夏日绘板!来画像素画!- 哔哩哔哩直播,二次元弹幕直播平台</title>,实质就是一项画画活动,每三分钟可以画一个点(感觉时间有点长了)……这里忍不住吐槽一下源码:
1 | <!--- |
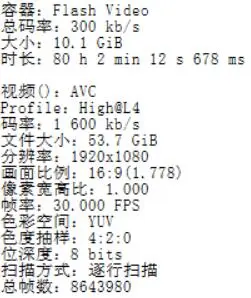
本来比较早就看到了这项活动,不过没放在心上,后来随着画板内容的爆满,才意识到可以尝试记录一下这项活动,正巧看到了av13032452,原理在简介里写的很清楚了:制作流程:使用autohotkey脚本每10秒截屏一次,然后使用irfanview批量裁剪+时间戳,最后使用ffmpeg压制,参数crf=0,yuv444,码率小于1500,测试b站能否通过。。但是这流程并不适合我,首先autohotkey就不会用……但是原视频效果很好,可以非常清楚地看到像素点的移动。过了一天发现居然有单独的直播间24h开放记录着,这就再好不过了,用 FFmpeg 保存 bilibili 直播视频。但是不久就忘记自己还在服务器上录制着,前几天突然想起来了,赶紧登上去看下,结果录制了80h了,文件10GB,这……1M小水管就不拖到本地吧,云端处理好得了,贴下media info:
起初是在百度云服务器处理,就是ffmpeg 加速视频播放,参考这里,这里有中文版,即在控制台运行ffmpeg -i "in.flv" -an -filter:v "setpts=0.002*PTS" out.flv,但是太慢了,于是就ftp传到了阿里云服务器(目前本人手中 CPU 性能最好的云服务器),好在时间在可以忍受的范围之内,几个小时便处理完了,把80多小时的视频缩短到了不到10 min。

最后下回本地,导入Pr(按照套路是拿小丸转成MP4再导入,因为Pr CC 2017不支持flv,但是这次居然没法转成MP4,无奈最后转成了mkv),加上自己喜欢的背景音乐以及浮夸的字幕说明,再导出媒体(用VBR,2 次,目标 1.6 M,最大 1.8 M参数画了半个小时),传到了 bilibili 。av13249656
压完感觉是失败之作,画面完全糊了,像素点根本没法看清,再想想 bilibili 再来个二圧,多半是废了,这一阶段就告一段落了……
但是,居然有第二阶段,也就是昨晚新的画板开启了,本来打算继续录以备不时之需,但是发现视频分辨率不是原来的1080P了,居然下降为720P了,然而我还是在录……
本地录制时不可能的(不要问我为什么),服务器上开Chrome录屏幕也是不可能的(只开浏览器就已经够卡的了)……那么问题来了,有没有什么比较好的方法,既省时又省力呢?2017-8-18 10:43:01:
| 标题 | 视频地址 |
|---|---|
| 【1080P】《夏日绘板》超 500 倍速回放 80h 片段测试 | av13249656 |
| 【60FPS】《夏日绘板》8.11-8.12 快放测试(OSU 瞩目) | av13286902 |
| 【120FPS】《夏日绘板》8.12-8.13 快放测试 | av13325904 |
| 【120FPS】《夏日绘板》8.13-8.14 片段快放测试 | av13342742 |
0x01.查阅资料
2017-8-16 13:51:52:
在这里、这里、这里和不知道是谁转谁的这篇虽然看到了HEADLESS CHROME,但是跟我想的还是有点不太一样(其实是不会用),所以以后再考虑用这个吧,现在还是用Selenium吧……
0x02.Selenium+Chromedriver——Screenshot
下载安装可参考此文:http://blog.jarjar.cn/first-selenium-python/ ,即pip install selenium和下载chromedriver_win32.zip并将其路径加入Path环境变量。
备注:Chromedriver有国内淘宝源:https://npm.taobao.org/mirrors/chromedriver
看了一堆资料,链接在文末,并反复试验,最终得出如下可行方案:
控制WebDriver.Chrome进入夏日绘板页面,向下滚动192之后截图(数据是反复试验所得),听起来很简单,实现的话如下代码:
1 | # -*- coding: utf-8 -*- |
这里有集合的关于Selenium的资料:http://blog.csdn.net/column/details/12694.html
http://www.51testing.com/zhuanti/selenium.html
感觉在这里放链接挺好(不过万一失效了是真没有办法、但是也不能全搬到这里吧,那也太占版面了),省的浏览器书签太多(至少上百千个)……
0x03.PIL——Timestamp&cut out
1 | # -*- coding: utf-8 -*- |
2017-8-17 07:23:39:
才发现写重复了,其实如下就可以了,怪不得跑起来怎么这么慢……
1 | # -*- coding: utf-8 -*- |
0x04.Rename
其实在0x03里你可能发现了含有重命名的代码,那么为什么不在那里直接处理呢……其实现在想想好像也可以的
就是有一个问题,一会儿用ffmpeg合并图片为视频时,对文件序列的命名有要求,需要是从0开始,并且需要补零,例如:我有三千张图片,就需要以0000、0001、0002……这样命名下去。py中有补零的方法,例如这里,但是我竟然不会用……
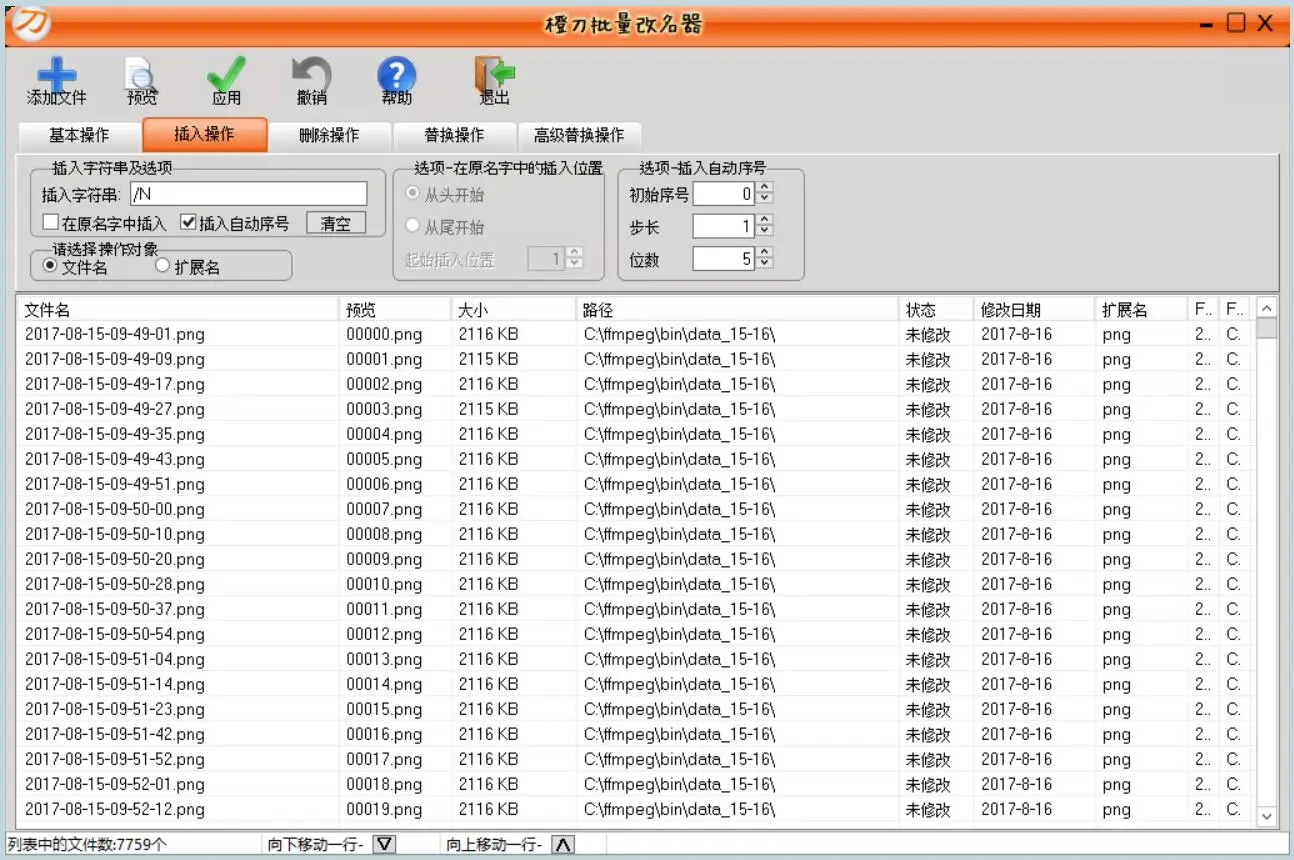
想起了以前在《电脑爱好者》里经常上镜的《拖把更名器》,但是用起来没有这个好——《橙刀批量改名器》
0x05.FFmpeg:Screenshot to Video
一行代码,控制台执行(需要在FFmpeg的bin目录下除非已经加入Path环境变量):
1 | ffmpeg -r 60 -i C:\ffmpeg\bin\data_8.15-16\%5d.png -vcodec libx264 -level 4.1 -crf 0 -pix_fmt yuv420p -b:v 4000k data_60_k.flv |
可以说最近两天,为了这一行代码,把vcb-s和小丸的教程看了个遍,总算知道一些简单参数的使用方法了
这好像是第一次在新站用markdown写表格,语法都忘了了……
| options | usage |
|---|---|
| -r | 帧率 |
| -i | 输入 |
| -vcodec | 指定编解码器 |
| -crf | |
| -pix_fmt | |
| -b:v | 限定视频码率 |
2017-8-22 21:09:25 补充:
中途遇到过bug:FFMPEG (libx264) “height not divisible by 2”,就是视频长宽不能是奇数,见此,解决,即-vf "scale=trunc(iw/2)*2:trunc(ih/2)*2"
0x06.x264
众所周知,目前bilibili视频码率限制为1800kbps,超过超清就要被二圧,我们当然是不喜欢二圧,所以网上有各种过时的不二压教程。由于0x05中-b:v限定跟实际产出相差甚远,没有参考,而且即使是产出小于其标准的视频也会被二圧(这俩天大概传了25+),官方投稿页面下有Biliencoder,后来在小丸那里才看见这是个过时的产物(在某次改革之后它并没有改),而我最初的投稿几乎都是用的这个,伤心……最近官方的投稿工具才自带压制功能的,但是我试了用这个也被二圧,这就很尴尬了……
终于,在第二天上午十点钟左右,第一个不二压视频产出,按照这个方法,第二个不二压视频也完美诞生。嗯,就是这样,是什么样呢,我还真就不想说,哎嘿嘿嘿……
0x07.测试总流程
好了,上面写了一大堆一张图也没有,现在可以适量放一些图上来了……
测试的时候用了三台云服务器,正式的时候两台就够了,所以这里就描述两台(也就是现在的方法)
首先(服务器软件安装配置环境略),运行截图(#0x02)脚本,即实时产出图片,来些数据看看:
| 服务器 | 日期范围 | 时间范围 | 好片 | 坏片 | 好片率 | 好片总大小 | 视频地址 |
|---|---|---|---|---|---|---|---|
cn-ali-hb2D-w2d&cn-tx-bj1-w2d | 8.13-8.14 | 9:48:22-9:48:22 | 6677 | 163 | 97.62 % | — | av13355499 |
cn-tx-bj1-w2d | 8.14-8.15 | 9:48:35-9:48:23 | 5516 | 222 | 96.13 % | 9.16 GB | av13394379 |
cn-bd-gzA-w2d | 8.15-8.16 | 9:49:01-9:44:36 | 7759 | 332 | 95.90 % | 15.80 GB | av13437598 |
cn-tx-bj1-w2d | 8.16-8.17 | 9:44:50-10:32:42 | 4918 | 133 | 97.37 % | NULL | av13468072 |
cn-tx-bj1-w2d | 8.17-8.18 | 10:32:54-10:08:44 | 6318 | 180 | 97.23 % | 11.80 GB | av13520949 |
cn-bd-gzA-w2d | 8.18-8.19 | 10:08:58-10:08:56 | 6939 | 101 | 98.57 % | 14.60 GB | av13561942 |
cn-tx-bj1-w2d | 8.19-8.20 | 10:08:05-10:59:06 | 4057 | 120 | 97.13 % | 8.04 GB | av13594048 |
cn-bd-gzA-w2d&cn-tx-bj1-w2d | 8.20-8.23 | 10:59:20-09:55:48 | 13755 | 357 | 97.13 % | 29.30 GB | av13713687 |
cn-ali-hb2D-w2d | 8.23-8.24 | 9:55:57-8:00:40 | 6592 | 9 | 99.86 % | 15.20 GB | av13750682 |
cn-tx-bj1-w2d | 8.24-8.26 | 8:00:08-8:23:41 | 9822 | 267 | 97.35 % | 20.20 GB | av13835523 |
cn-ali-hb2D-w2d&cn-tx-bj1-w2d | 8.26-8.27 | 8:56:39-20:14:20 | 7245 | 168 | 97.73 % | NULL | av13888048 |
cn-ali-hb2D-w2d&cn-tx-bj1-w2d | 8.27-8.28 | 20:14:27-12:51:29 | 5392 | 16 | 99.70 % | NULL | av13915498 |
cn-ali-hb2D-w2d&cn-tx-bj1-w2d | 8.28-8.29 | 12:51:38-12:27:53 | 5726 | 238 | 96.01 % | NULL | av13984275 |
cn-ali-hb2D-w2d&cn-tx-bj1-w2d | 8.29-8.30 | 12:26:49-16:31:04 | 6854 | 246 | 96.54 % | 9.37 GB | av13991058 |
cn-ali-hb2D-w2d | 8.30-8.31 | 12:26:49-16:31:04 | 5395 | 34 | 99.37 % | 9.93 GB | av14020054 |
9392 5.85 GB 22-57-01 13-23-25
发现百度云服务器的弹性公网还有4天(也就是8.21)就要到期了……最便宜(1兆带宽)的23/月感觉不是很便宜……
渣渣统计
测试时是用两台服务器分时截图,主要是害怕服务器空间不够,万一图片存不下就GG了,然而今天还就真满了,登百度云服务器一看C盘就剩6MB了,想起上次阿里云服务器被我搞成就剩NTFS 0B,还能远程登录上去……但是两台的缺点是分别合成两段视频之后还得合并,限于带宽和繁琐程度就不如在一台上搞了,上面说的两台其实是交换的意思,你一天我一天的……
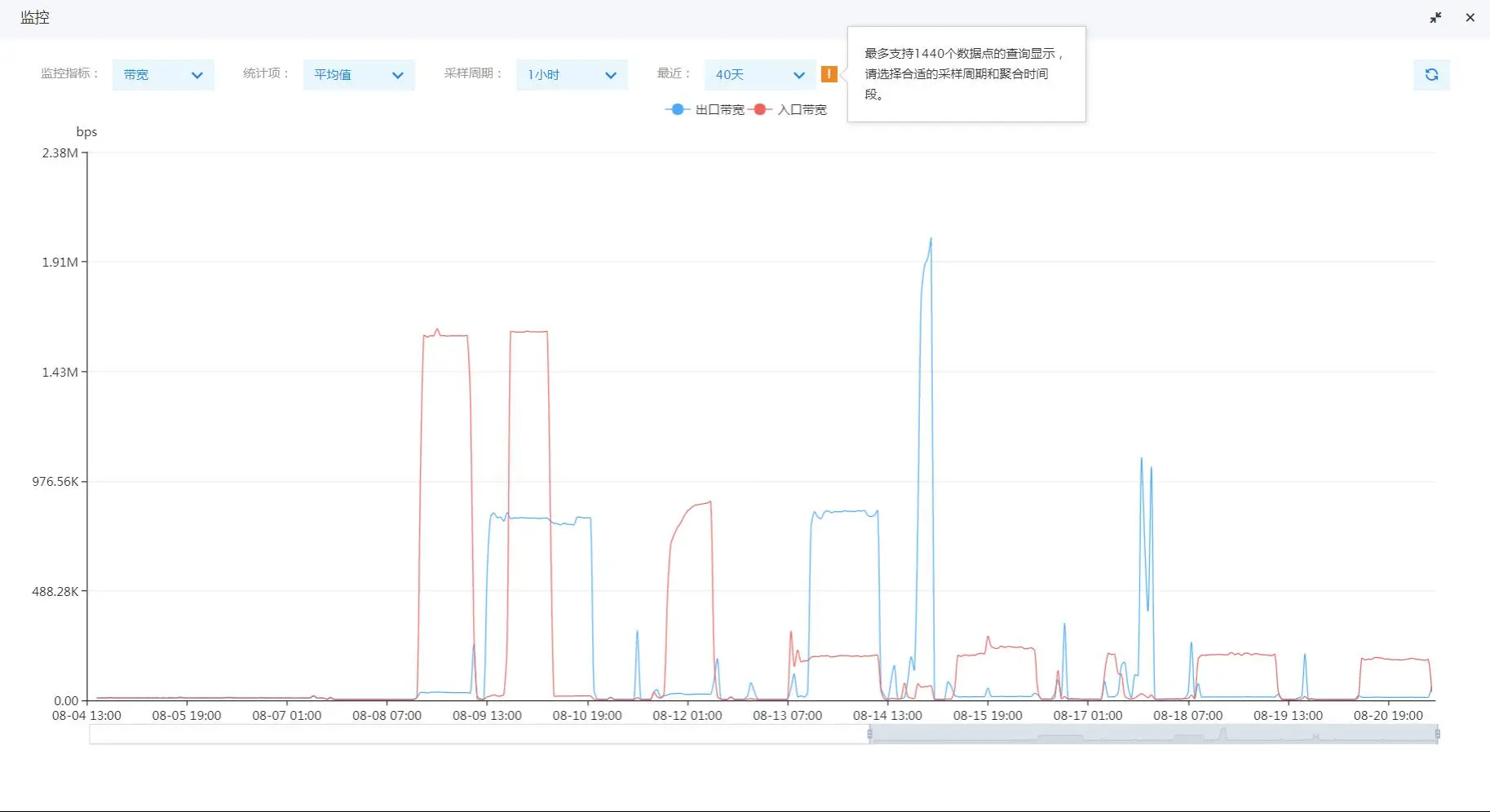
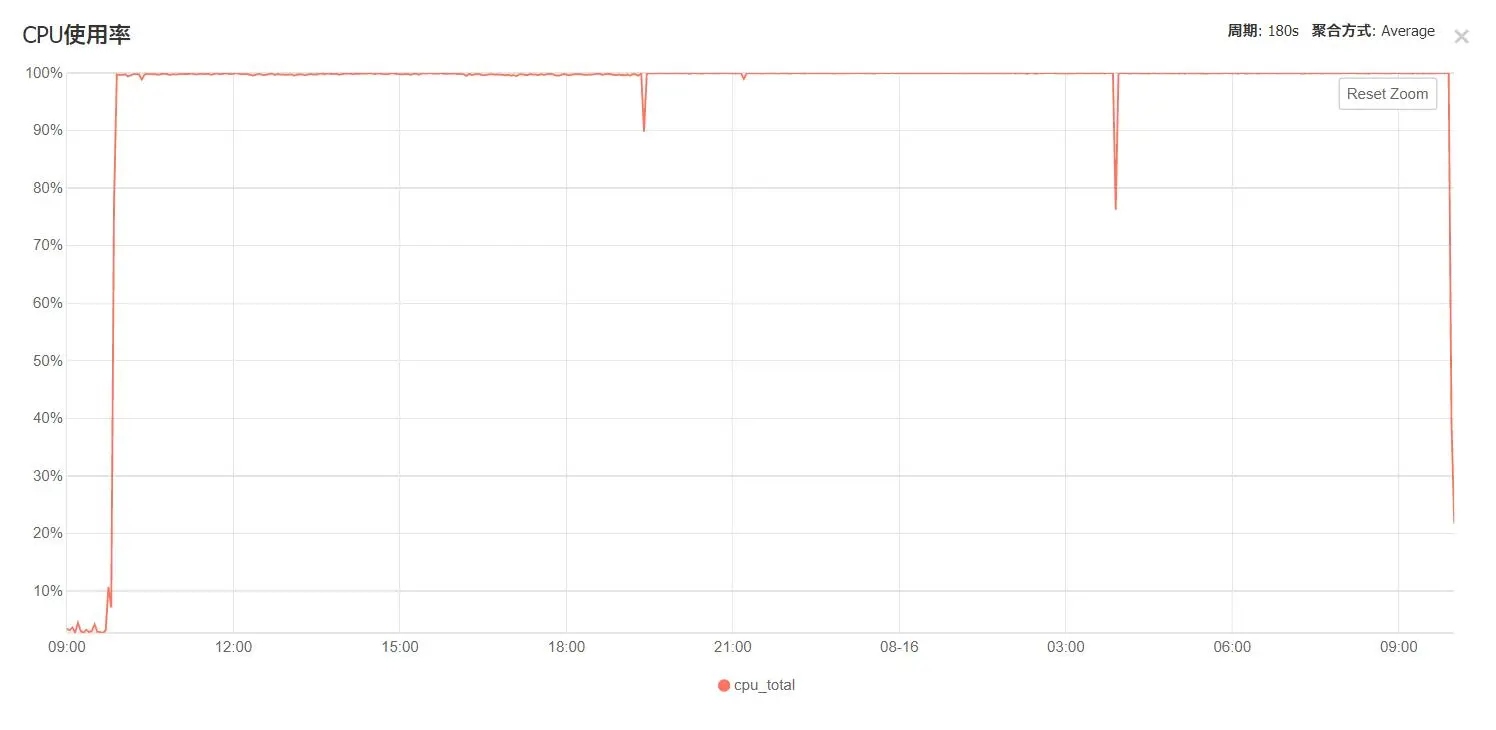
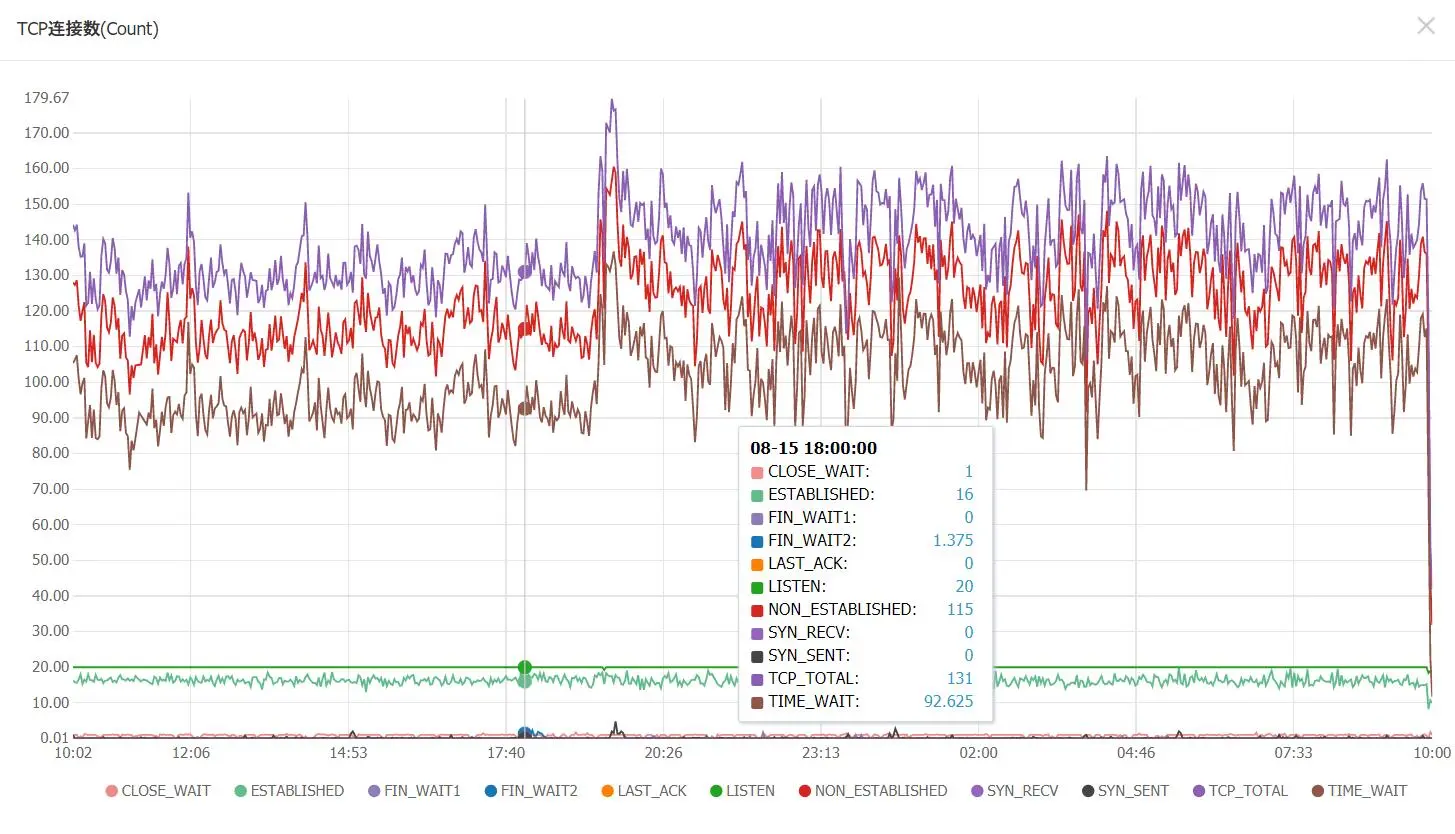
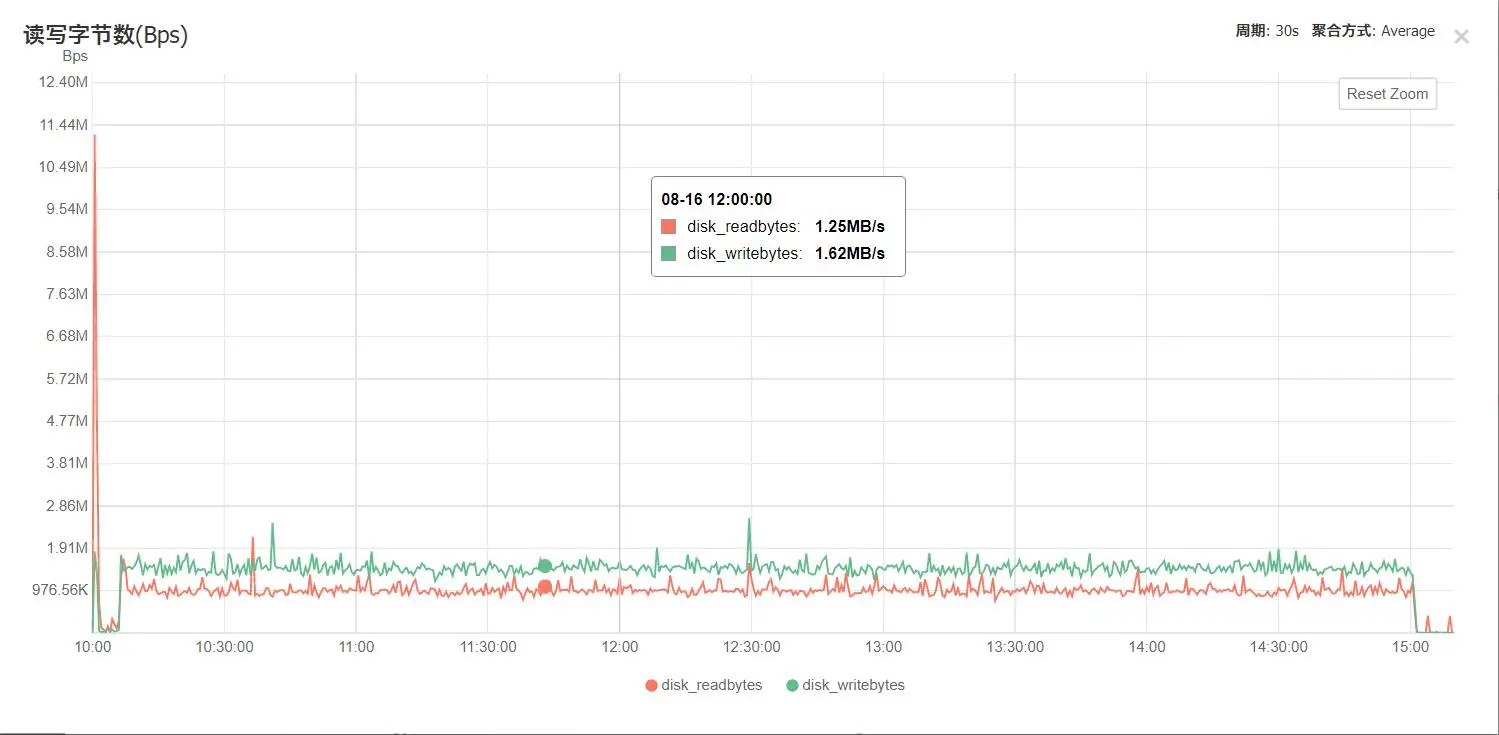
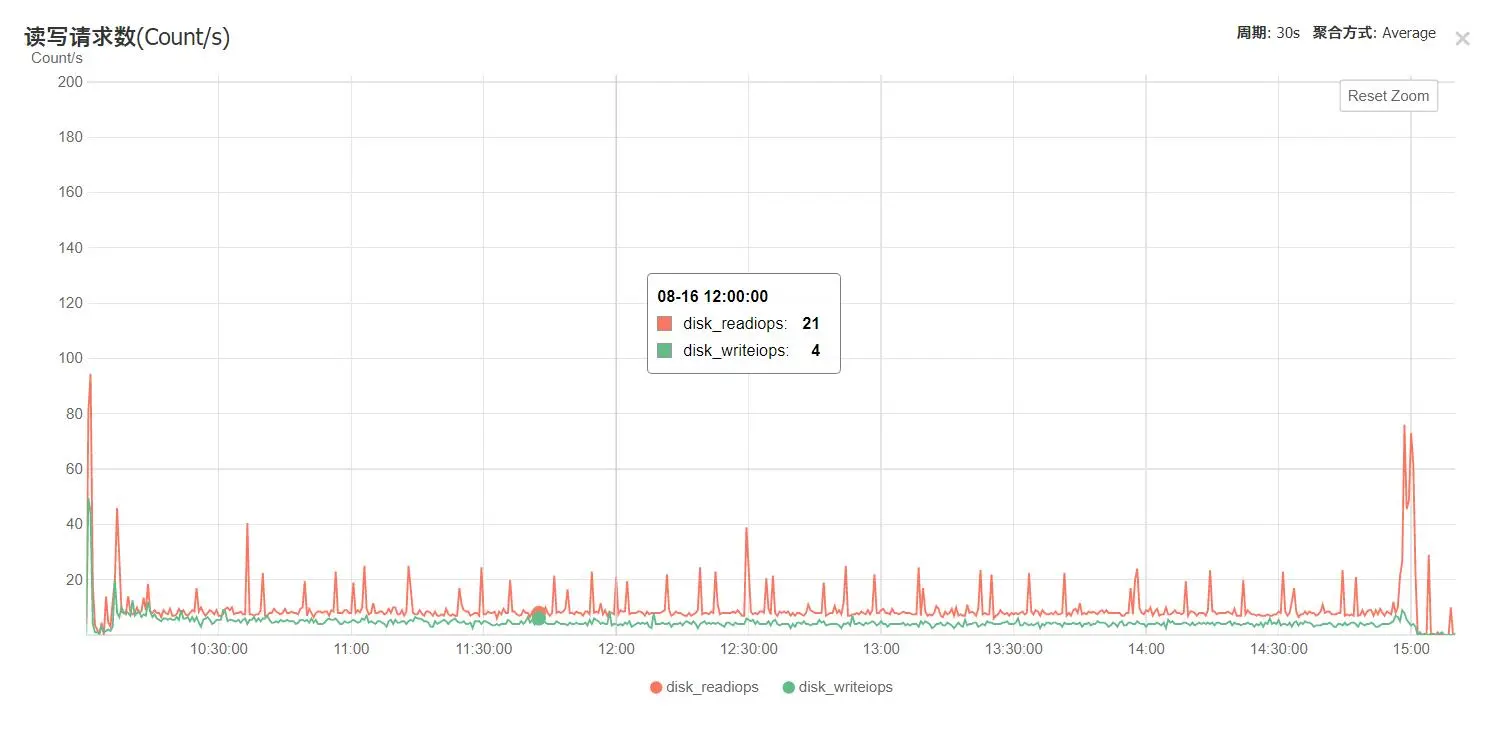
此时云服务器几乎处于CPU打满状态:
截图如无特殊说明,均为cn-bd-gzA-w2d 8.15-8.16
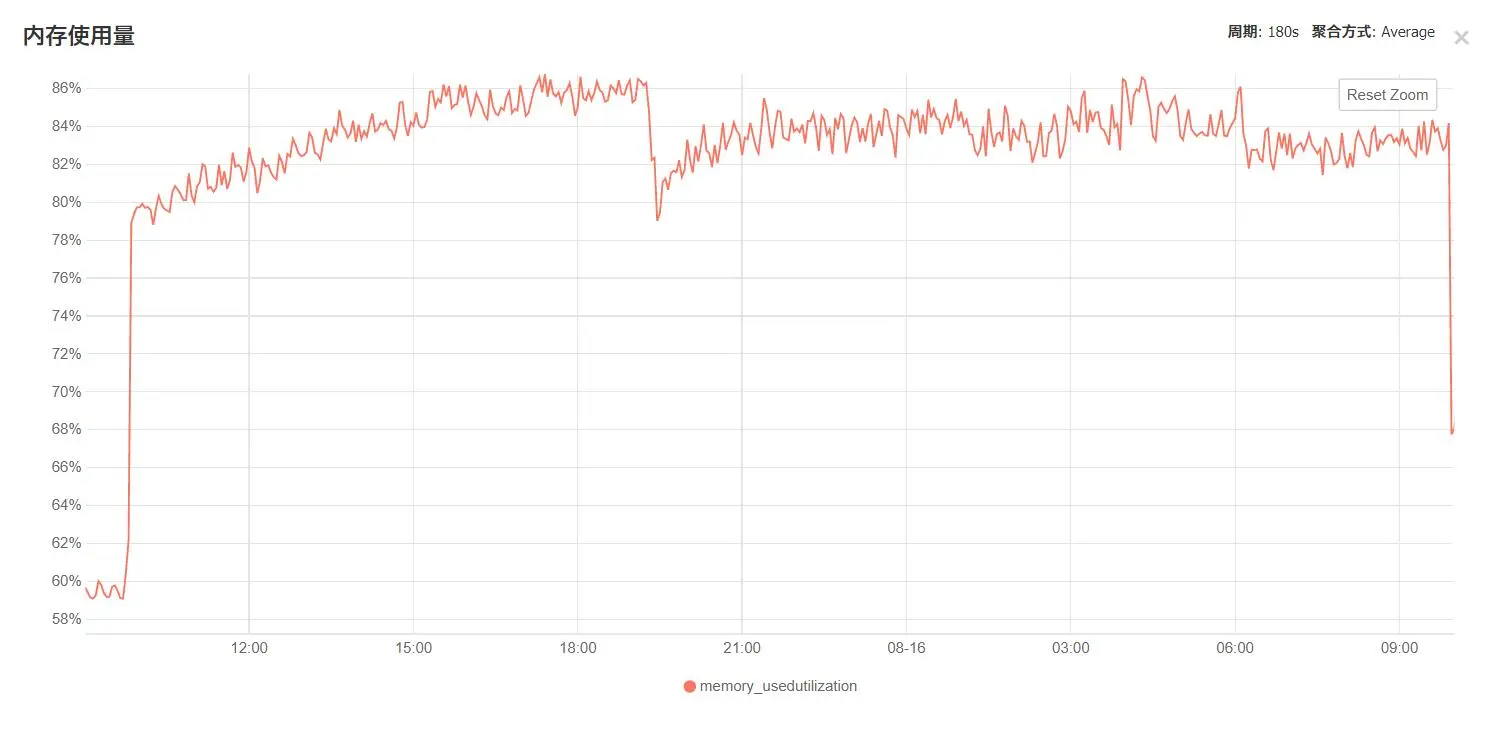
内存占用也不小:
磁盘满了:
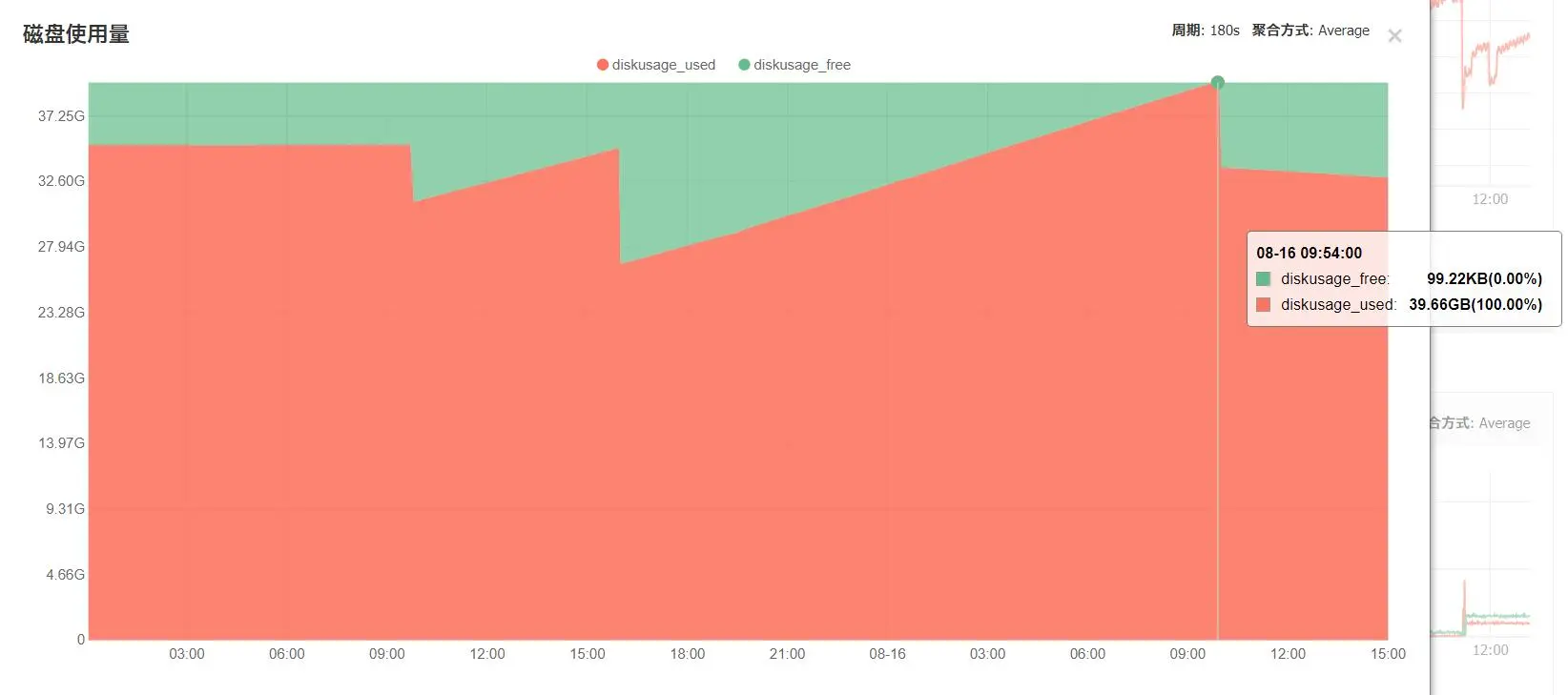
其实磁盘满了这是个意外,具体原因暂不明……
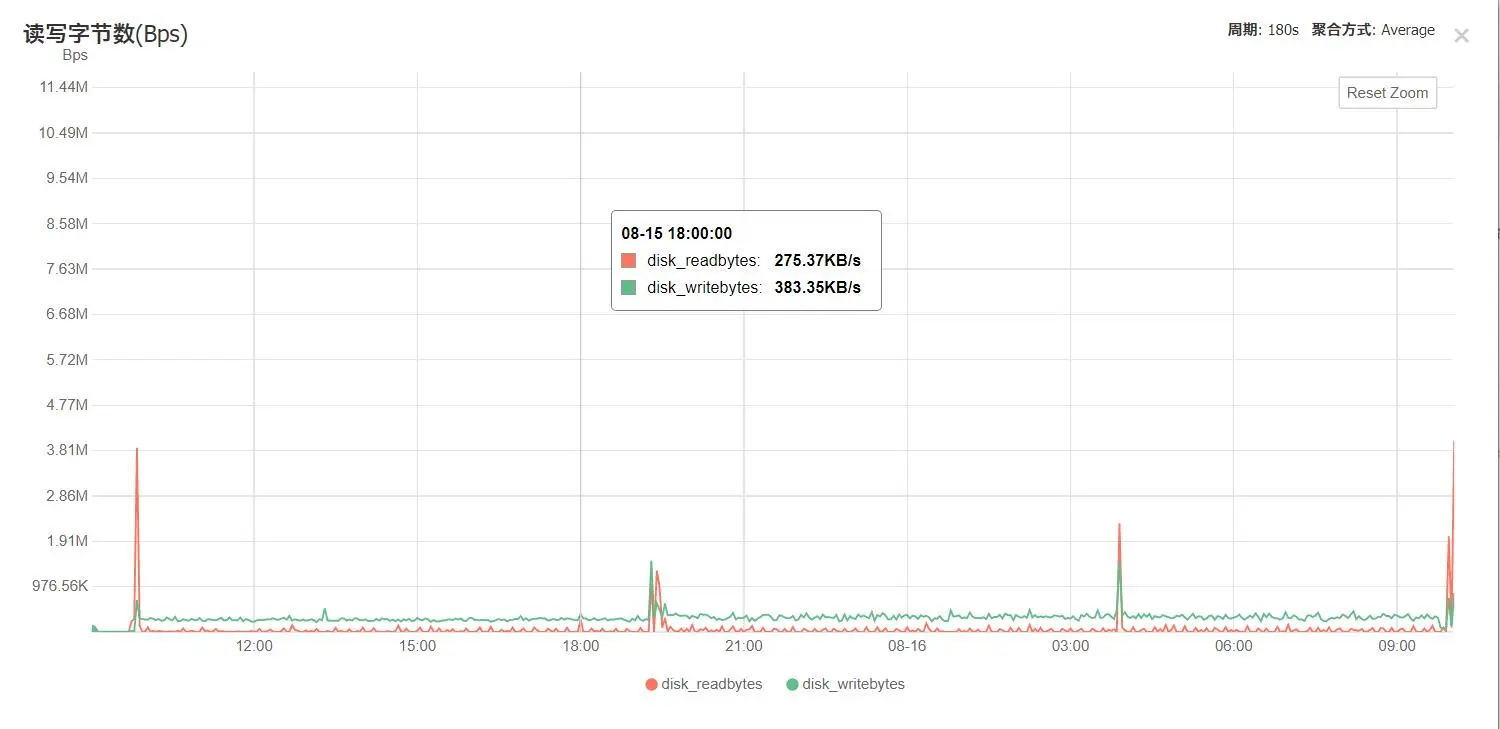
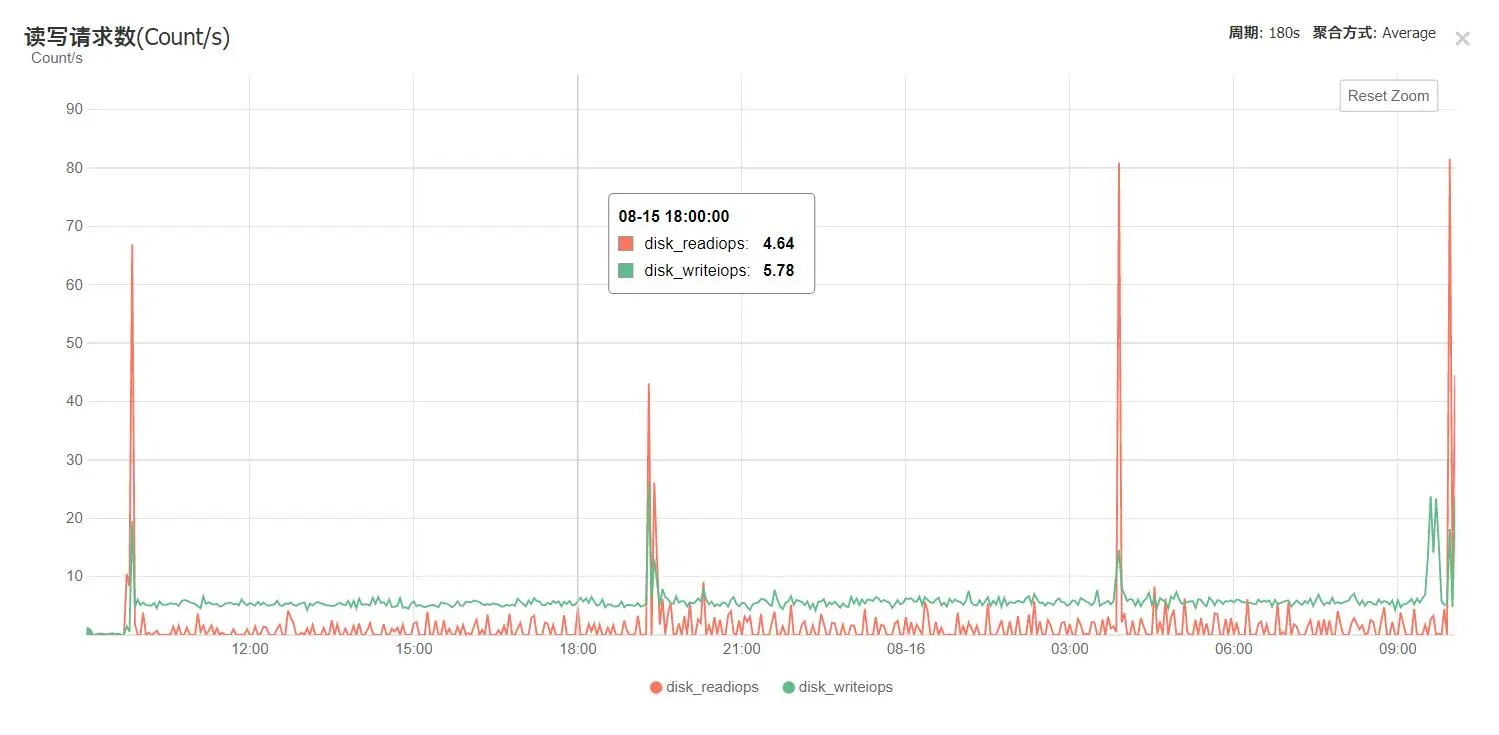
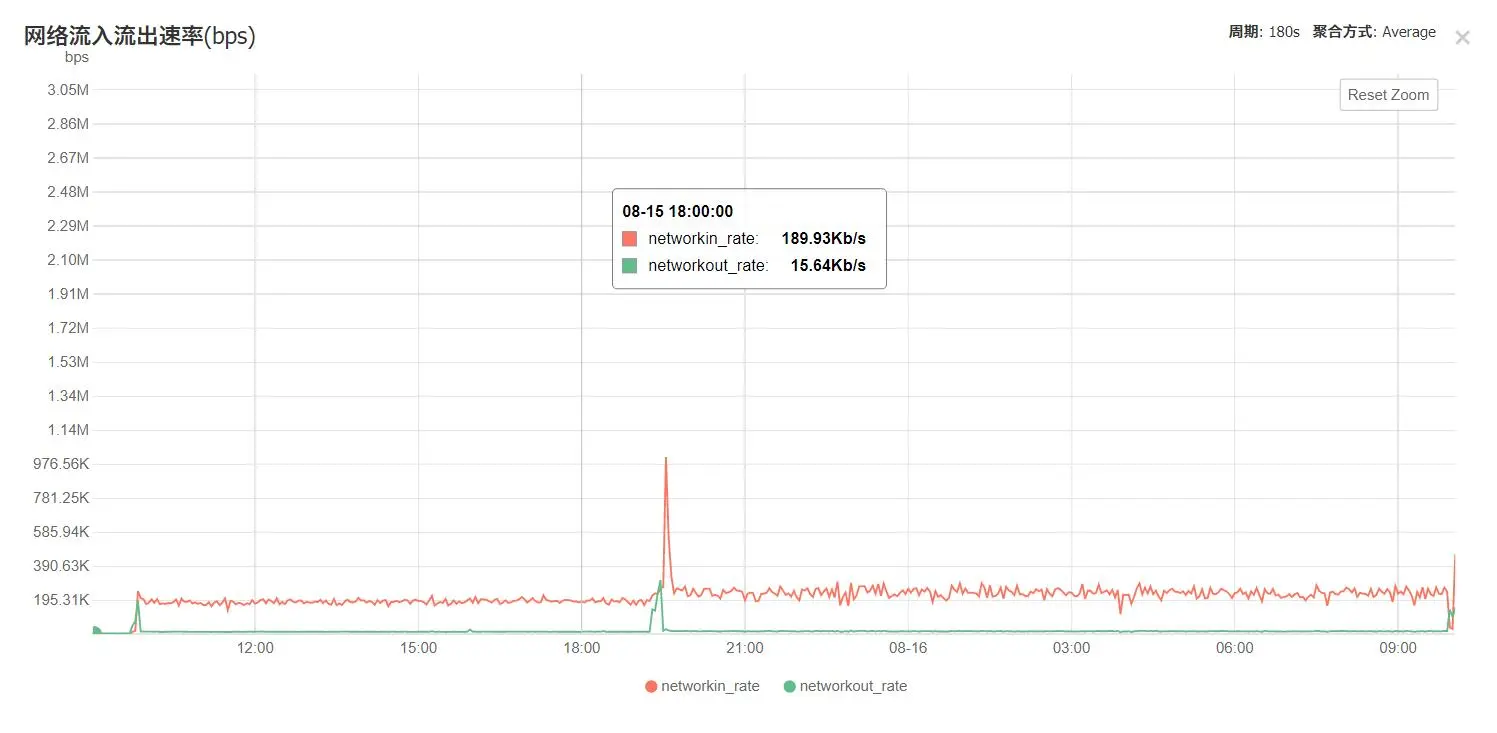
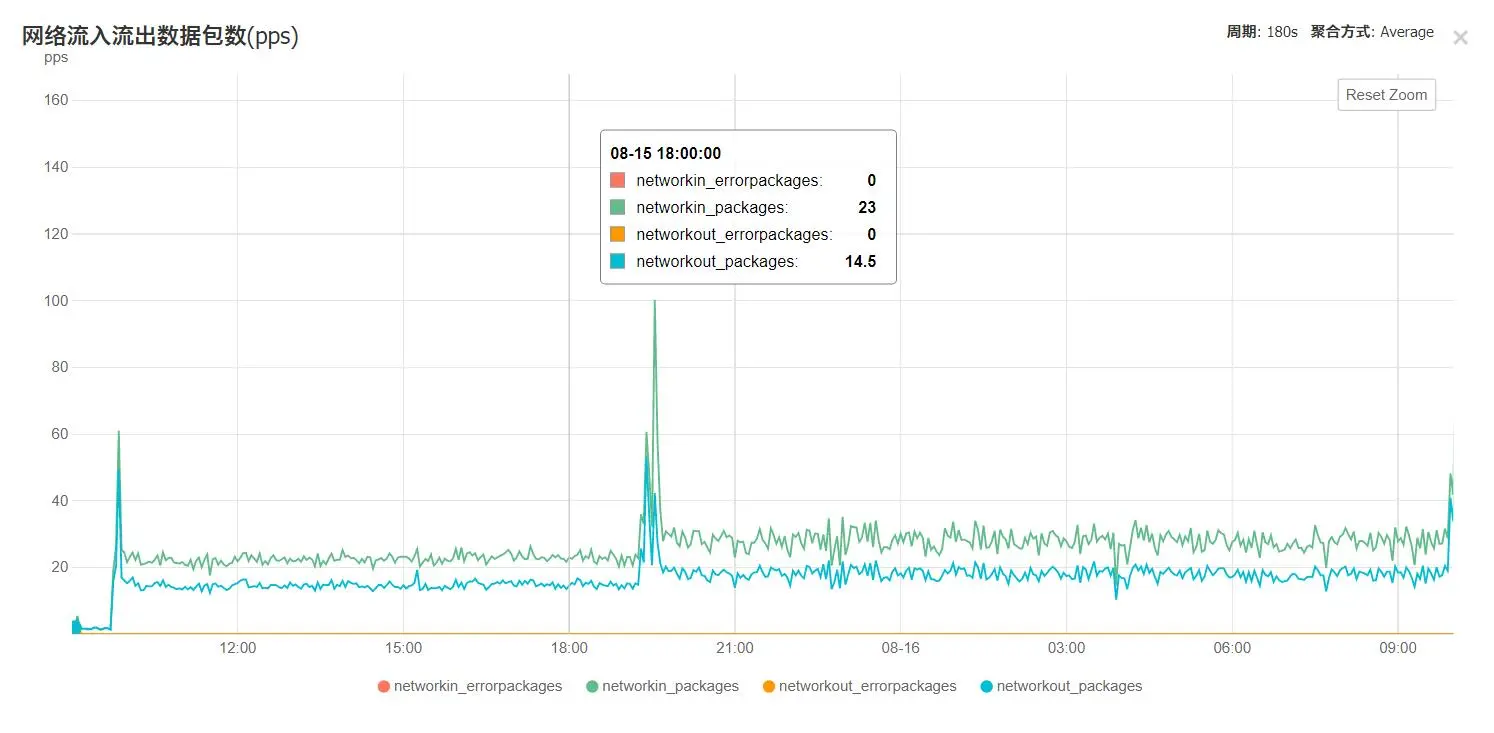
然后,存好24h之后就远程登陆上去,按文件大小排序,小于2MB的就是坏片,删之,上个图更好说明:
来一小段看下坏片分布情况:
运行图片处理脚本,可能是我写的不科学等种种原因,CPU也打满了……


无网络操作就不截网络相关的图了……
图片处理完就像这样:

接下来用《橙刀改名器》改名:
下一步,FFmpeg生成视频:
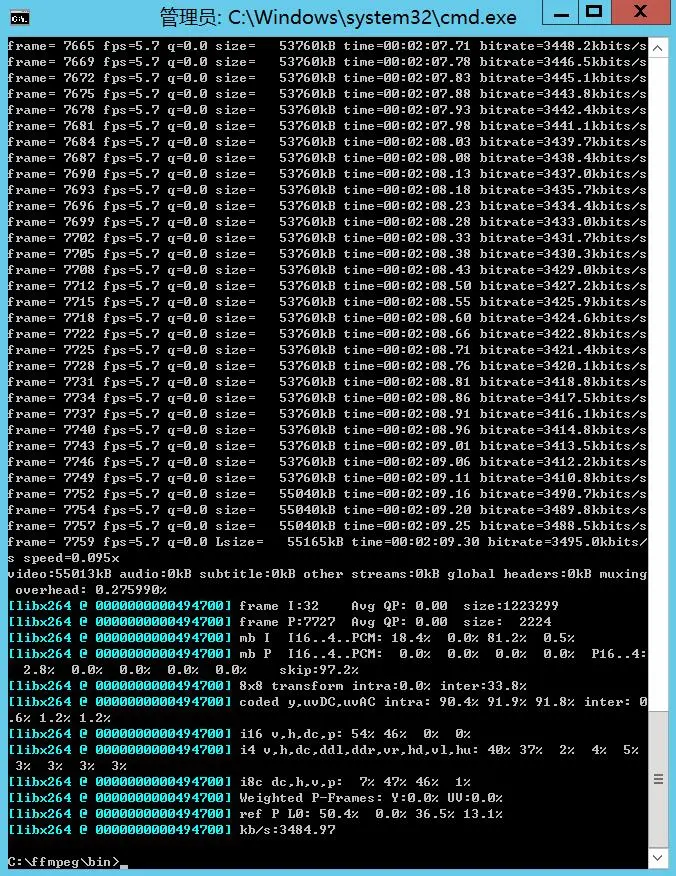
1 | ffmpeg -r 60 -i C:\ffmpeg\bin\data_8.15-16\%5d.png -vcodec libx264 -crf 0 -pix_fmt yuv420p data_60_420.flv |
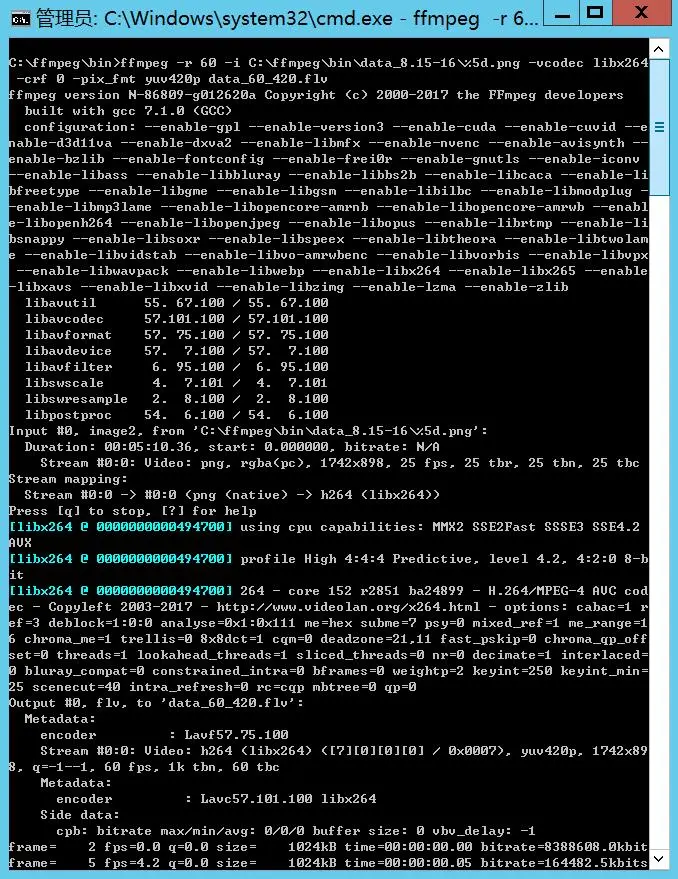
生成完成(约35min),这次的时间算是长的了:

最后一步,小丸压制,当然官方的工具也要压一遍做对照组……
传到bilibili就 ok 了!
整个流程就是这样子的……
0x08.后记
写了三个小时写不动了……
0x09.引用
python selenium自动化(三)Chrome Webdriver的兼容
使用Python+Selenium对网页进行截图
利用 Python + Selenium 实现对页面的指定元素截图(可截长图元素)
利用Python+Selenium截取DOM(某个网页元素)
