感冒已经持续一周却不见好转的说~
0x00.前言
这次是真·直播写……回想起来就是上周的这个时候在教学楼靠窗边,虽然我把窗户全关上了,但是还是很冷,我就趴了一会没睡着,下午回宿舍睡了一觉醒来觉得嗓子疼,好在第二天的《信号与系统》二考不是很严重,现在成绩出了还好是过了(二考能刷分什么的对我来说是不存在的)。emmm……感冒直到现在还没好,WTF
作为bilibili一名不起眼的UP主,对于我来说,刚开始的稿件来源几乎都是自行裁剪的番剧的OP、ED(请无视第一个稿件),后来开始搬运油管上的(毕竟首发速度相当快),毕竟刚开始没粉丝这一阶段(审核速度也很慢、稿件经常撞车、各种版权被锁)是必须经历的,中途也经历过一天投数个稿件掉粉严重的现象,不过为了更多粉丝暂时就这么做了……中途暑假的《夏日绘板》,本来就是想用最好的技术水准记录一下娱乐而已,没想到最后引来了这么多人(部分引流来自《萌娘百科》),几乎后几天每个视频播放量都1K +,这阶段增加的粉丝数比我上一学期(约4个月)的总数都要多。于是,做视频的要求提高了,非必要尽量不搬运(少搬运)油管,增加原创作品数量,其目的不过还是为了提高自己的技术水准而做出更高质量的视频给粉丝们……
上面好像有点说多了(不删了),那么这次想做一个splash合集,就是这样。
0x01.查阅资料
通读PIL文档,即使是汉化的也可以,不过汉化作者还是推荐RTEM(Read The English Manual))
0x02.准备工作
首先,数据来源是BiliPlus的关于页的客户端启动splash记录。
下文如无特殊声明,均用
BP替代BiliPlus
拿数据很简单,可以这样:
1 | # -*- coding: utf-8 -*- |
为了不重复访问BP,把结果复制到一个文本文件中,并根据.json内容区分出三种类型:
1.失效数据
举例:
1 | 20160309_12-ab8d441e.json {"code":0,"message":"success","result":[{"id":3901100,"animate":1,"duration":2,"platform":"IOS","startTime":1457452800,"endTime":1457538900,"thumbUrl":"http://i0.hdslb.com/group1/M00/93/49/oYYBAFbfjy-AdjVMABiMAEQK2ck895.jpg?/8df93f3ac2769949a768de2e122d8965.","times":5,"type":"default"}]} |
猜测这时候bilibili还没启用bfs,因为thumbUrl访问的结果是404,所以这段时间(20160207_16-3171b367.json 788B-20160309_12-ab8d441e.json 289B:共17条.json数据、31张图片)的图片现均不可用。
2.可用数据之类型一(不含TTL)
举例:
1 | 20160314_00-4d1bca42.json {"code":0,"message":"success","result":[{"id":3901257,"animate":1,"duration":2,"platform":"IOS","startTime":1457884740,"endTime":1457971140,"thumbUrl":"http://i0.hdslb.com/bfs/archive/69fca7faf1b6b159613f042abdce6d69bc55f227.jpg?/44b9b94f5d1a5397eba0105a63d045a1.","times":10,"type":"default"}]} |
很明显是启用了bfs,随便试了几个都可以正常访问,时间段(20160314_00-4d1bca42.json 295B-20170611_20-e18c8089.json 519B:共173条.json数据、432张图片)
3.可用数据之类型二(含TTL)
举例:
1 | 20170630_00-91ca5641.json {"code":0,"data":[{"id":522,"type":1,"animate":1,"duration":2,"start_time":1498636800,"end_time":1498838340,"thumb":"http://i0.hdslb.com/bfs/archive/3afefb263f3a282f2bfba6f0abcab820ae219b59.jpg","hash":"86fa91e5a6d21ebbc3e916dfd3ac1264","times":5,"skip":1,"uri":"http://www.bilibili.com/blackboard/topic/activity-BJEHXeuXZ.html"},{"id":206,"type":4,"animate":1,"duration":3,"start_time":1480058707,"end_time":1480490708,"thumb":"http://i0.hdslb.com/bfs/archive/54282e5017a3775fef1ac77e37d66b732f071743.png","hash":"b7be29596e6cb78e06edc8e51c4d3a73","times":1,"skip":0,"uri":""}],"message":"","ttl":1,"ver":"13234343026192087504"} |
增加了TTL(虽然不知道有什么用处),试了几个也可以正常访问,时间段(20170630_00-91ca5641.json 629B-20170908_04-19bcfad0.json 610B:共81条.json数据、188张图片)
注:上述数据均为原始数据,后续去重本数据不再更新
失效数据只能抛弃,先处理可用数据一
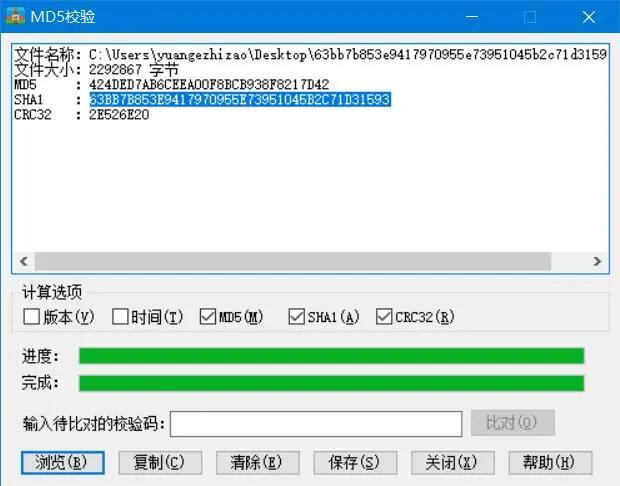
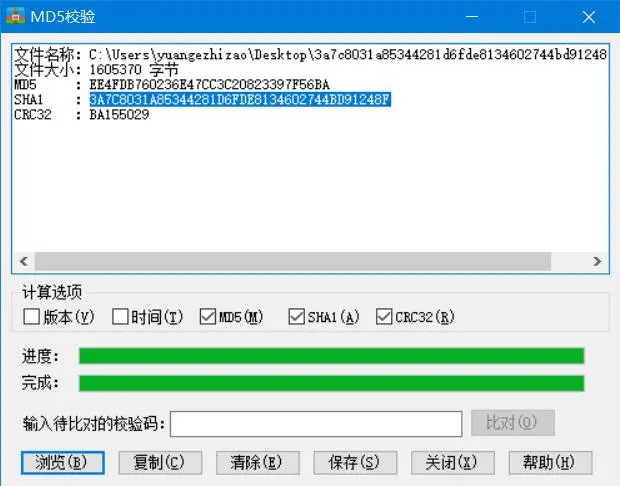
链接为:http://i0.hdslb.com/bfs/archive/69fca7faf1b6b159613f042abdce6d69bc55f227.jpg?/44b9b94f5d1a5397eba0105a63d045a1.
经过测试,.jpg文件名69fca7faf1b6b159613f042abdce6d69bc55f227为SHA1,?后的44b9b94f5d1a5397eba0105a63d045a1为MD5……然而并没有什么卵用(要是在这里再校验一步MD5的话我只能说真是闲……)
那么现在是时候保存下来了,文件名取SHA1(本来准备用id,后来发现相同id有的有多个图片),可以这样:
1 | # -*- coding: utf-8 -*- |
输出结果:
1 | C:\Python27\python.exe C:/Users/yuangezhizao/PycharmProjects/splash_fetch/demo.py |
把文件放好:

0x03.图片先知
可以看出分辨率是:2732 x 2048综合考虑长宽各缩放一半为佳。
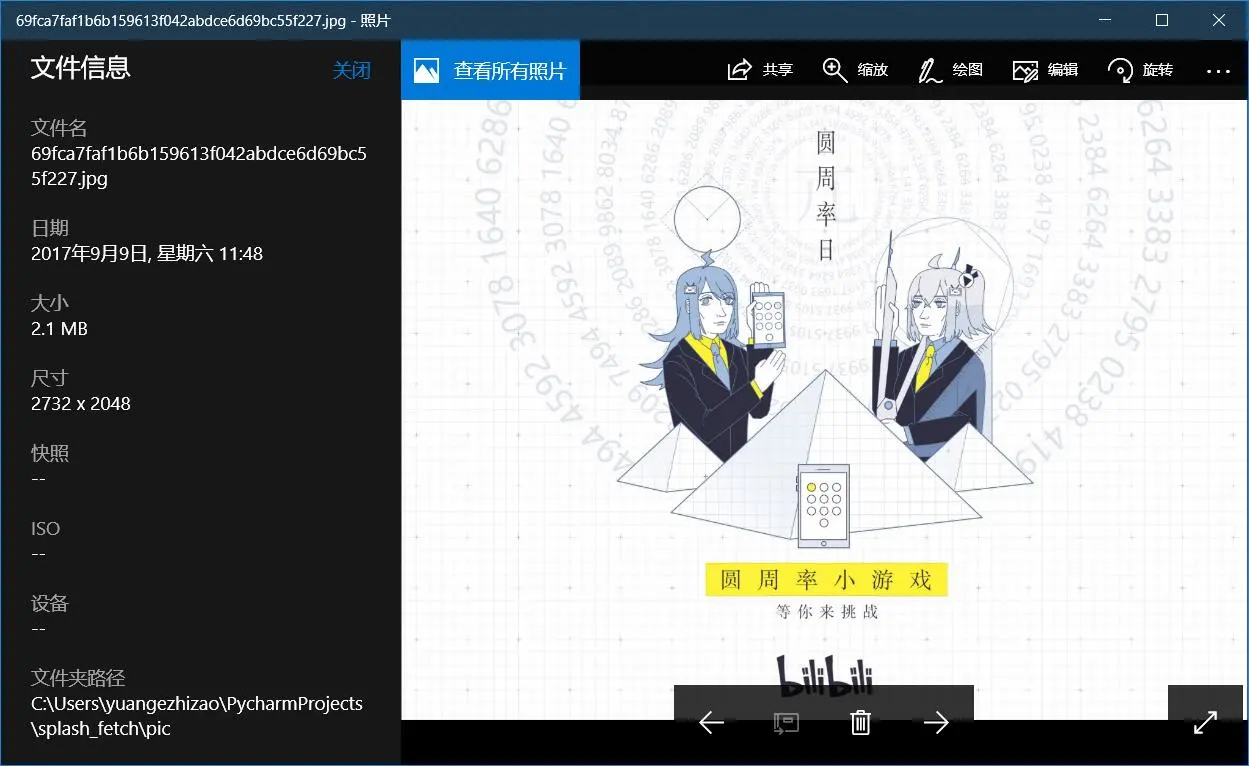
贴一张分辨率分别缩小一半之后的效果:
发现20160421_20-a3c99e08.json开始加入了data,举例:
1 | 20160421_20-a3c99e08.json {"code":0,"data":[{"id":71,"animate":1,"duration":2,"platform":"IOS","startTime":1461286800,"endTime":1461384000,"thumbUrl":"http://i0.hdslb.com/bfs/archive/b6d057b310a5ed6ac8b604e58a36b56dcbd1308f.jpg?/ac9cc99fc93283d0dcbc71695a9fe06b.","times":3,"type":"opertion"}]} |
emmm……文件不同MD5一样?看来是我想多了,后者的MD5是假的

emmm……唯一的一条20160425_16-70b6b72f.json {"code":0,"data":null}可以删了……
我果然是该吃饭了,刚才一个小时在手动删掉重复的url,刚才试了直接下载就可以,就算你重复save_img也只会存一张图片……
于是之前的不变,后续做如下更改:
1 | for line in fileinput.input("1.txt"): |
输出结果(占版面已删除)
呀,忽略了[1]以及[24]……那就再放进去吧……
emmm……我还是再订一份鸡吧(饿的受不了了)……才想起来为什么不在服务器上操作……
此处省略在服务器上的一系列操作,结果就是现在图片都下载好了……
0x04.PIL——processing……
首先,查看图片信息,可以这样:
1 | # -*- coding: utf-8 -*- |
输出结果:
1 | JPEG (2732, 2048) RGB |
第一种最多,异常分辨率的只有两张……
1 | for line in fileinput.input("3.txt"): |
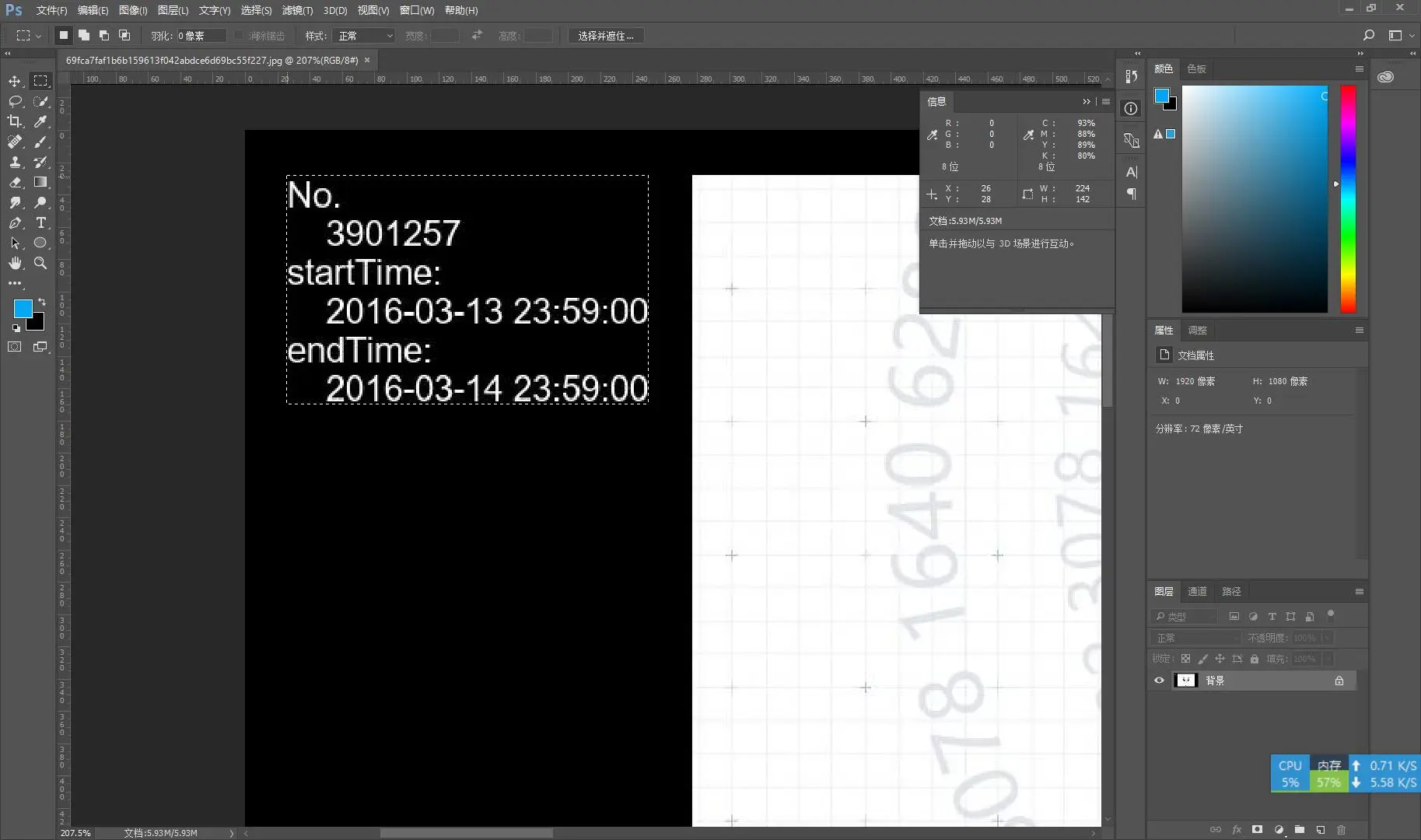
第一阶段的几张在本地处理,思路是先生成一张1920 x 1080的黑色图片为基底,然后打开一半原图1366 x 1024,把它居中(需要手动计算)放在基底图片上,最后上水印保存即可
原图居中计算:
1 | 1920 - 1366 = 554 |
于是坐标便是(277, 28, 1643, 1052)
至于水印的坐标,拖进PS大概瞄一眼就好了,对了,有个好方法就是每次保存完图片调用img.show(),虽然官方说打开文件效率并不高,不过这减少了一次手动打开图片的操作,能省下很多时间……
综上所述,可以这样:
1 | # -*- coding: utf-8 -*- |
好了,11.txt处理完之后,可以搞1.txt了……想了很长时间,决定还是得动用数据库查重
考虑到有重复存在:从另一文件夹取图片保存至本目录下,其实只要确定有图片存在的情况下不要覆盖就好啦
又考虑到文件名:时间戳 + 哈希为好,毕竟顺序还是很重要的
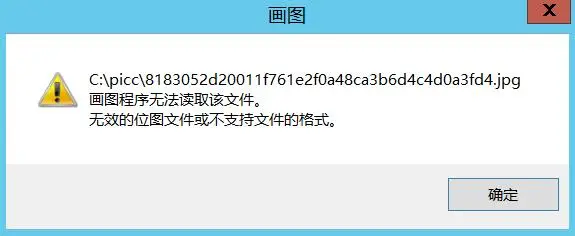
1 | 8183052d20011f761e2f0a48ca3b6d4c4d0a3fd4.jpg |
emmm……系统画图打不开,web预览纯黑,估计是遇到什么bug了吧……
3.txt的,可以这样:
图片变为2048 x 2732的……
重新计算原图居中(想了半天没想明白于是打开了PS,最后在画图里得到了答案):
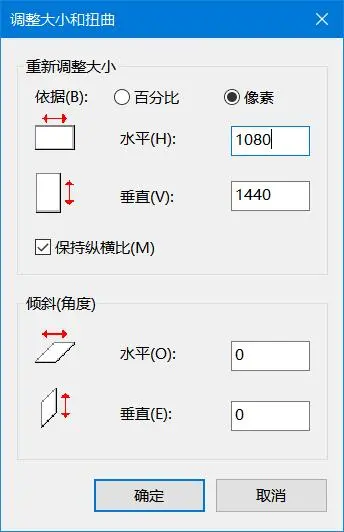
不对,下面这个是对的
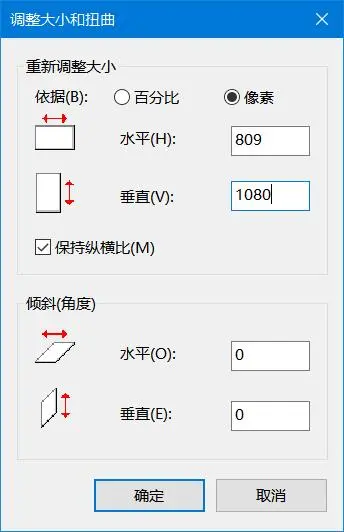
综合考虑:809 x 1080
1 | 1920 - 1080 = 1111 |
1 | # -*- coding: utf-8 -*- |
看到图片数量不大,于是从服务器打包下回本地,得重命名下。最终决定前10位时间戳保留,后两位SHA1也留下
第一次遇到改名失败14762880002535d48d9dc511eb5aa4a307724cdd68710b4bb1.jpg
遇到Win迷之排序问题,决定写程序改成日期
不在同一目录下的路径问题实在是太尴尬了……
突发奇想想把SHA-1放到视频里(或者贴张二维码),这样想要一张图片的话也不用下整个图包,不过,转瞬之间就打消了念头,谁会手打那么长……
现在网速普及下个图包应该很简单吧……
不过uri还是要加上的
1 | # -*- coding: utf-8 -*- |
前面还有4个空格,所以再加上
还有一只漏网之鱼,夏日挑战赛链接过长……
部分图片黑屏综合考虑剔除
例:http://i0.hdslb.com/bfs/archive/47fe7ab64ad00e1ca552617d2eb27019450458cb.jpg
不过作画失误还是保留,全场包邮般的笑声(个别地区除外)……
那么现在该处理剩下的两张分辨率异常的图片了:
还是拿起笔和纸吧,这样算起来比较快一点……
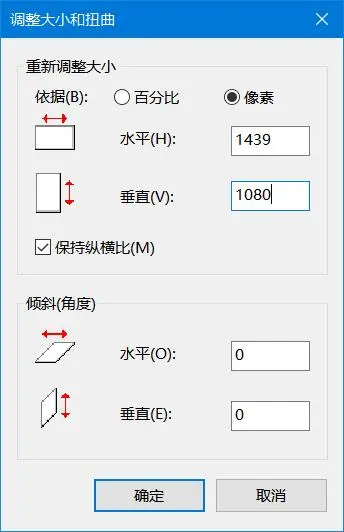
1439 x 1080
处理完按照文件名的日期顺序排序,重命名000.jpg-220.jpg,后缀名不必改(因为处理过程中已经解决了)
0x05.图片转视频
还是用ffmpeg:
1 | ffmpeg -r 0.5 -i C:\ffmpeg\bin\2016\%3d.jpg -vcodec libx264 -level |
帧率0.5也就是一张图片停留2s
0x06.后记
爆肝了三天,终于做完了……
发现420p码率未超1800于是加上音频合并直传
但是444p码率2007暂时放弃
