[120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 69.69848251342773s split_all_content completed in 69.70153331756592s bulk_load_to_es_by_thread_pool_executor count 12 completed in 95.28210115432739s 二测 ===== Test Start ===== generate_all_content completed in 62.697731256484985s split_all_content completed in 62.69972372055054s bulk_load_to_es_by_thread_pool_executor count 12 completed in 84.10340571403503s
[120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 69.1796202659607s split_all_content completed in 69.1828773021698s bulk_load_to_es_by_thread_pool_executor count 12 completed in 93.98494386672974s 二测 ===== Test Start ===== generate_all_content completed in 60.939237117767334s split_all_content completed in 60.94171929359436s bulk_load_to_es_by_thread_pool_executor count 12 completed in 82.97677779197693s
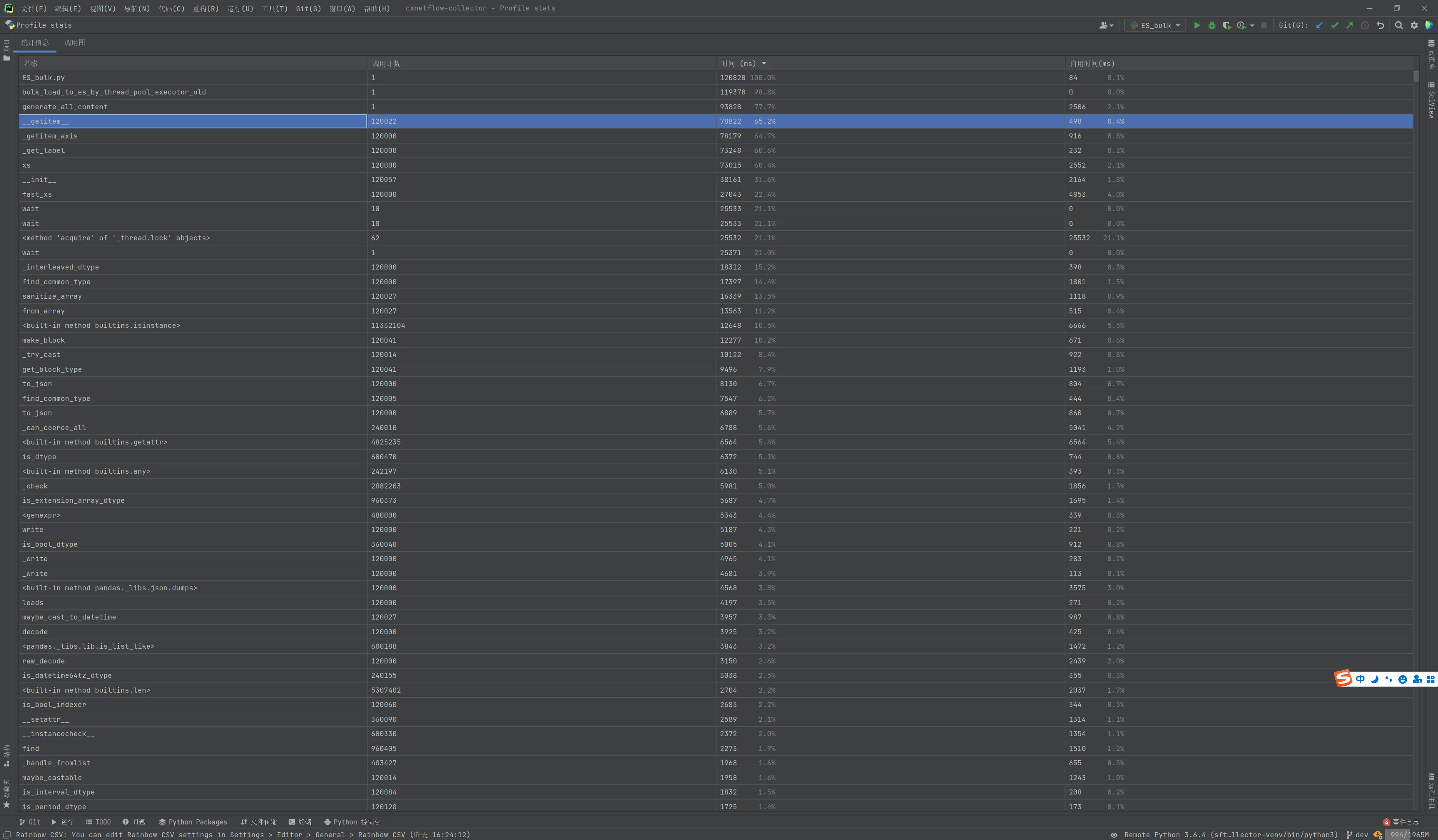
可以用PyCharm里运行菜单中的Profile查看详细的调用时间,虽然里面的名称不一定是认识的
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
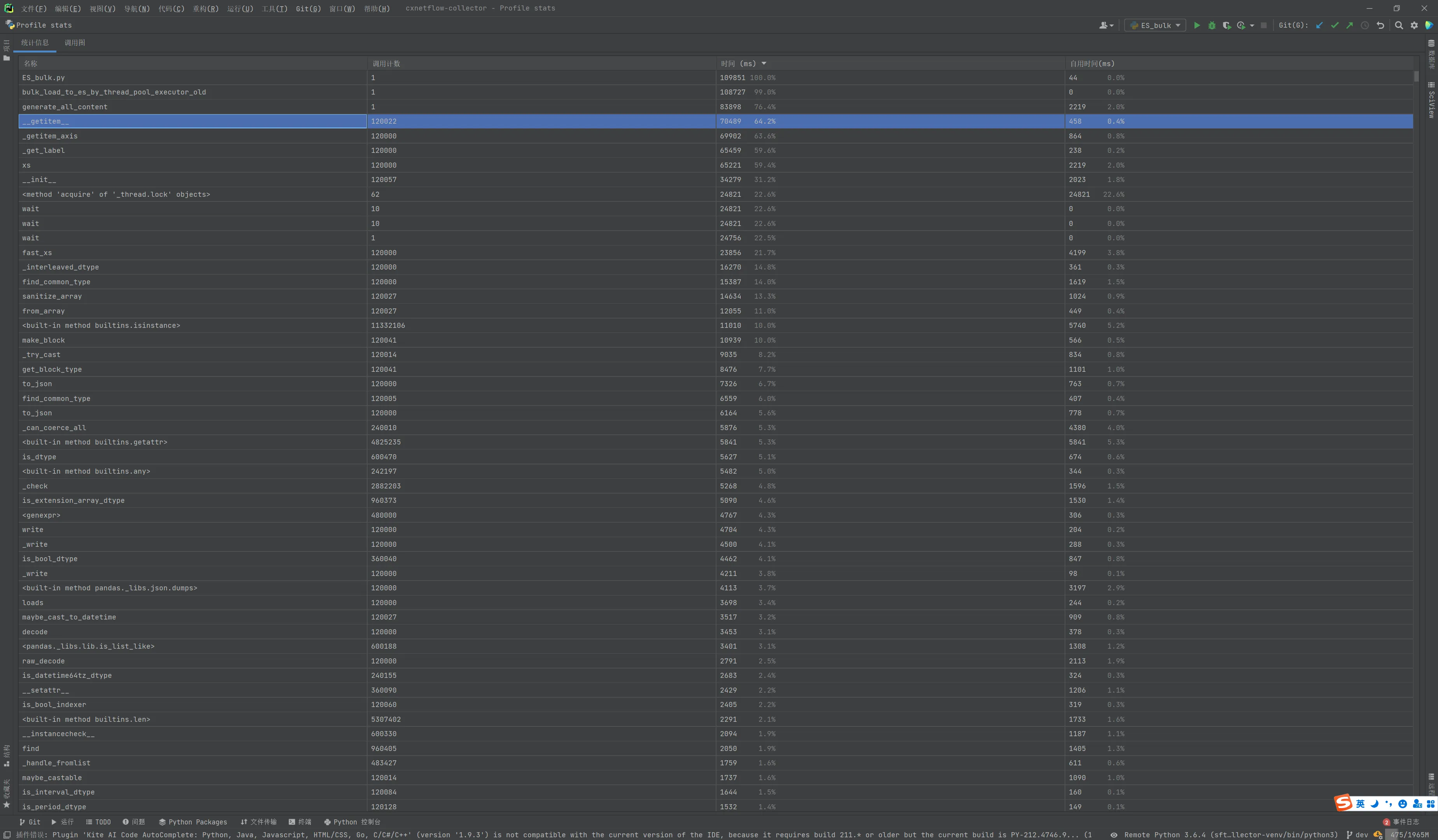
ssh://<rm>:22/home/sdn/collector-venv/bin/python3 -u /root/.pycharm_helpers/profiler/run_profiler.py 0.0.0.0 54982 /home/sdn/cxnetflow-collector/test/ES_bulk.py Starting cProfile profiler …… [120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 93.82941246032715s split_all_content completed in 93.8325982093811s bulk_load_to_es_by_thread_pool_executor count 12 completed in 119.37008118629456s Snapshot saved to /tmp/cxnetflow-collector3.pstat 二测 [120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 83.8989508152008s split_all_content completed in 83.90175294876099s bulk_load_to_es_by_thread_pool_executor count 12 completed in 108.72677087783813s Snapshot saved to /tmp/cxnetflow-collector.pstat
[120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 48.11659097671509s split_all_content completed in 48.11987543106079s bulk_load_to_es_by_thread_pool_executor count 12 completed in 76.74760866165161s 二测 ===== Test Start ===== generate_all_content completed in 38.85774374008179s split_all_content completed in 38.86009979248047s bulk_load_to_es_by_thread_pool_executor count 12 completed in 60.861244201660156s 三测 ===== Test Start ===== generate_all_content completed in 37.29048800468445s split_all_content completed in 37.29290556907654s bulk_load_to_es_by_thread_pool_executor count 12 completed in 61.13431143760681s
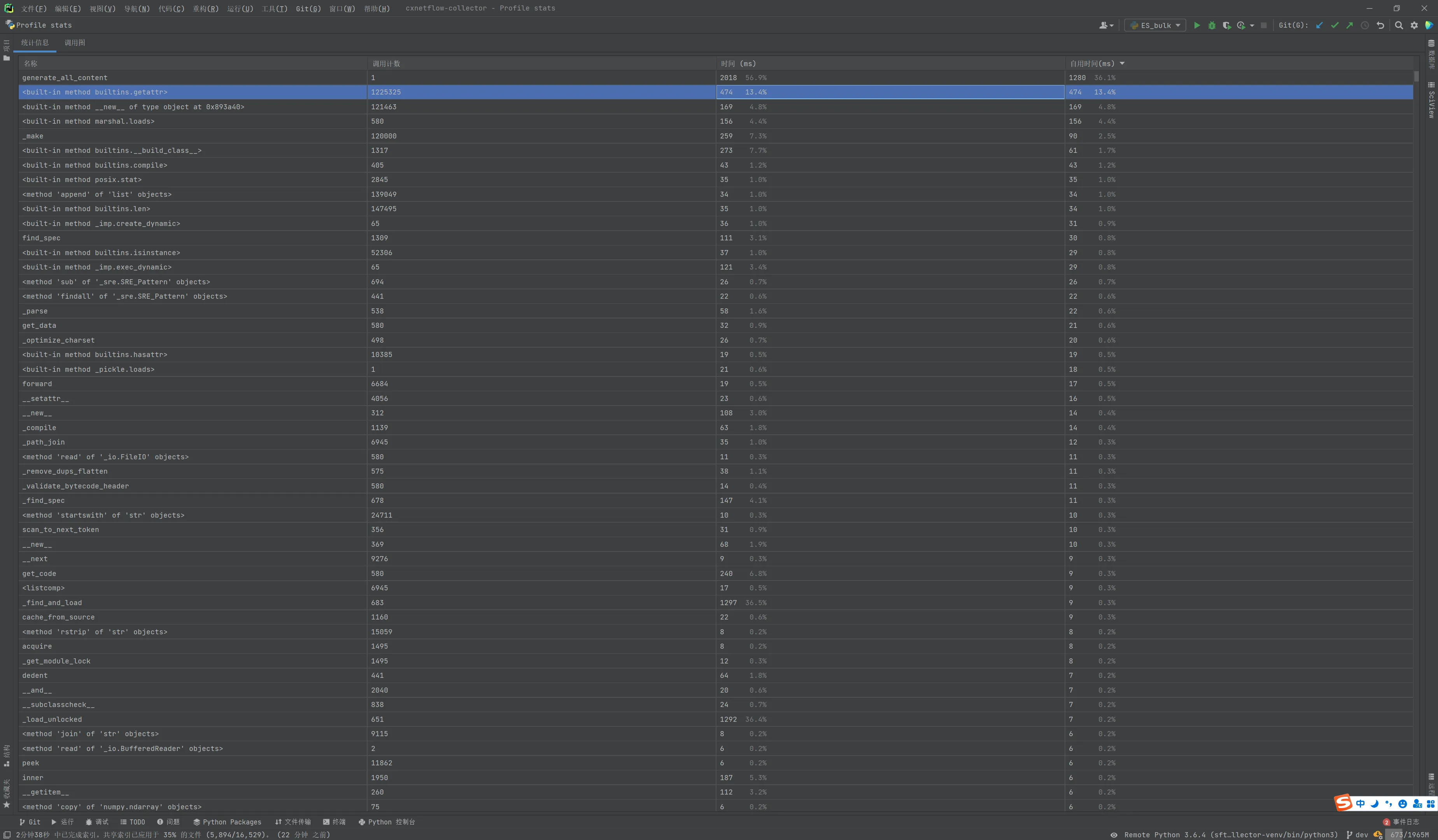
同样,拿Profile再跑一遍
1 2 3 4 5 6 7 8
一测无 二测 [120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 56.07292437553406s split_all_content completed in 56.07504391670227s bulk_load_to_es_by_thread_pool_executor count 12 completed in 77.29125237464905s Snapshot saved to /tmp/cxnetflow-collector1.pstat
[120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 1.2253265380859375s split_all_content completed in 1.2275893688201904s bulk_load_to_es_by_thread_pool_executor count 12 completed in 23.280734062194824s
担心没有生成正确的内容还特意去看了下返回值,确认是正确的
content
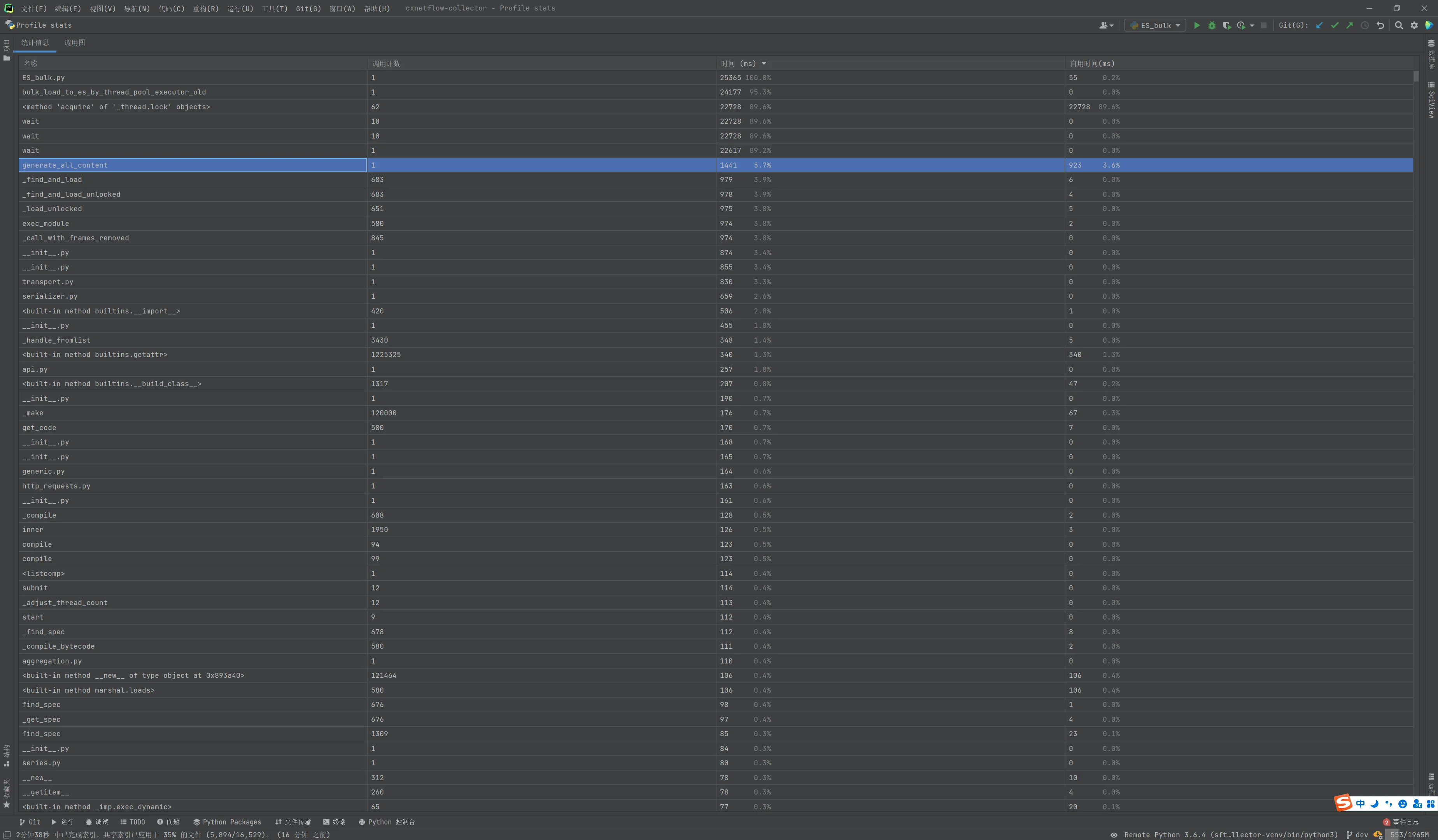
惯例跑一遍Profile看看
1 2 3 4 5 6
[120000 rows x 10 columns]> ===== Test Start ===== generate_all_content completed in 1.442192554473877s split_all_content completed in 1.4444100856781006s bulk_load_to_es_by_thread_pool_executor count 12 completed in 24.176409482955933s Snapshot saved to /tmp/cxnetflow-collector2.pstat