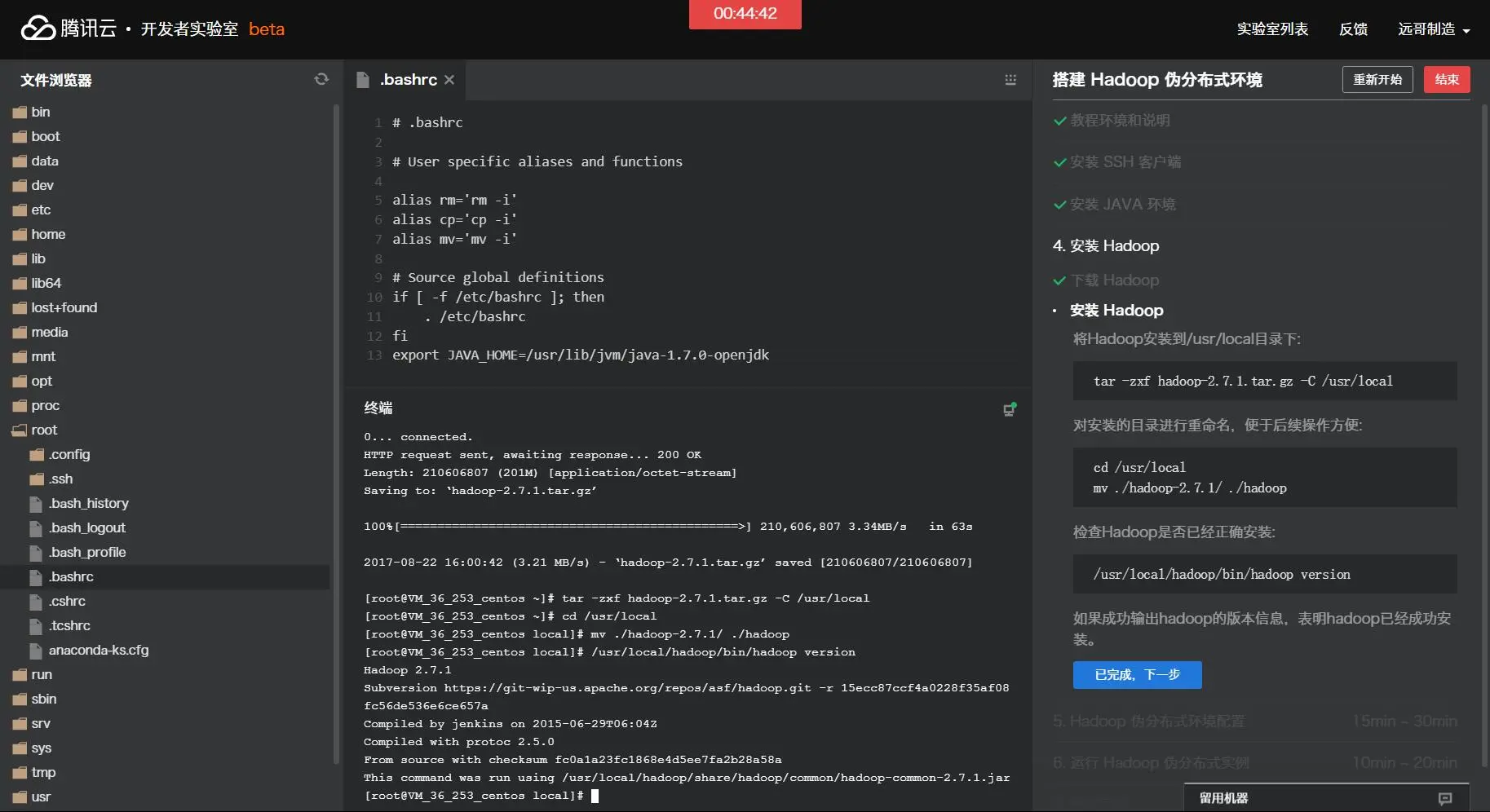
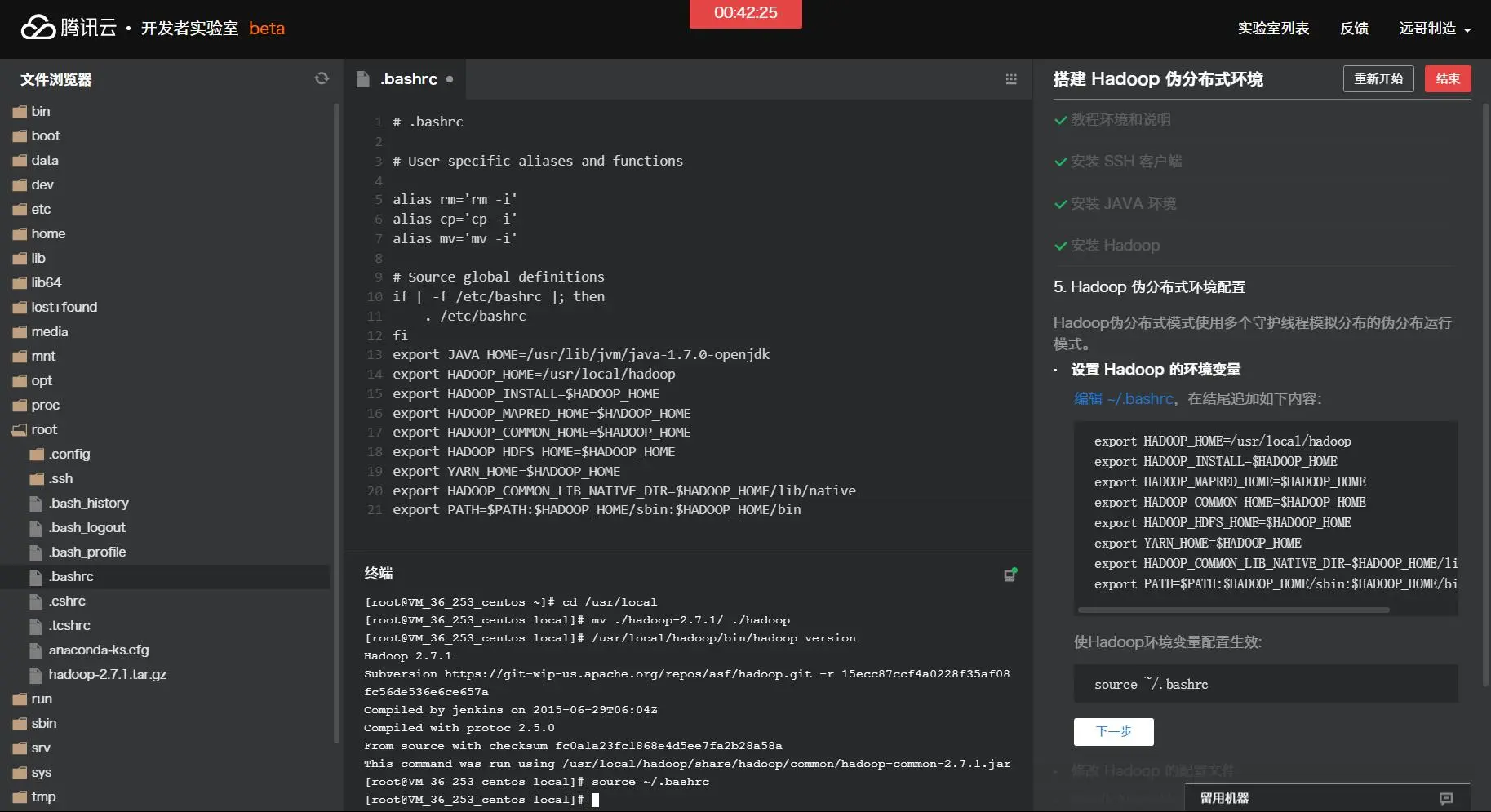
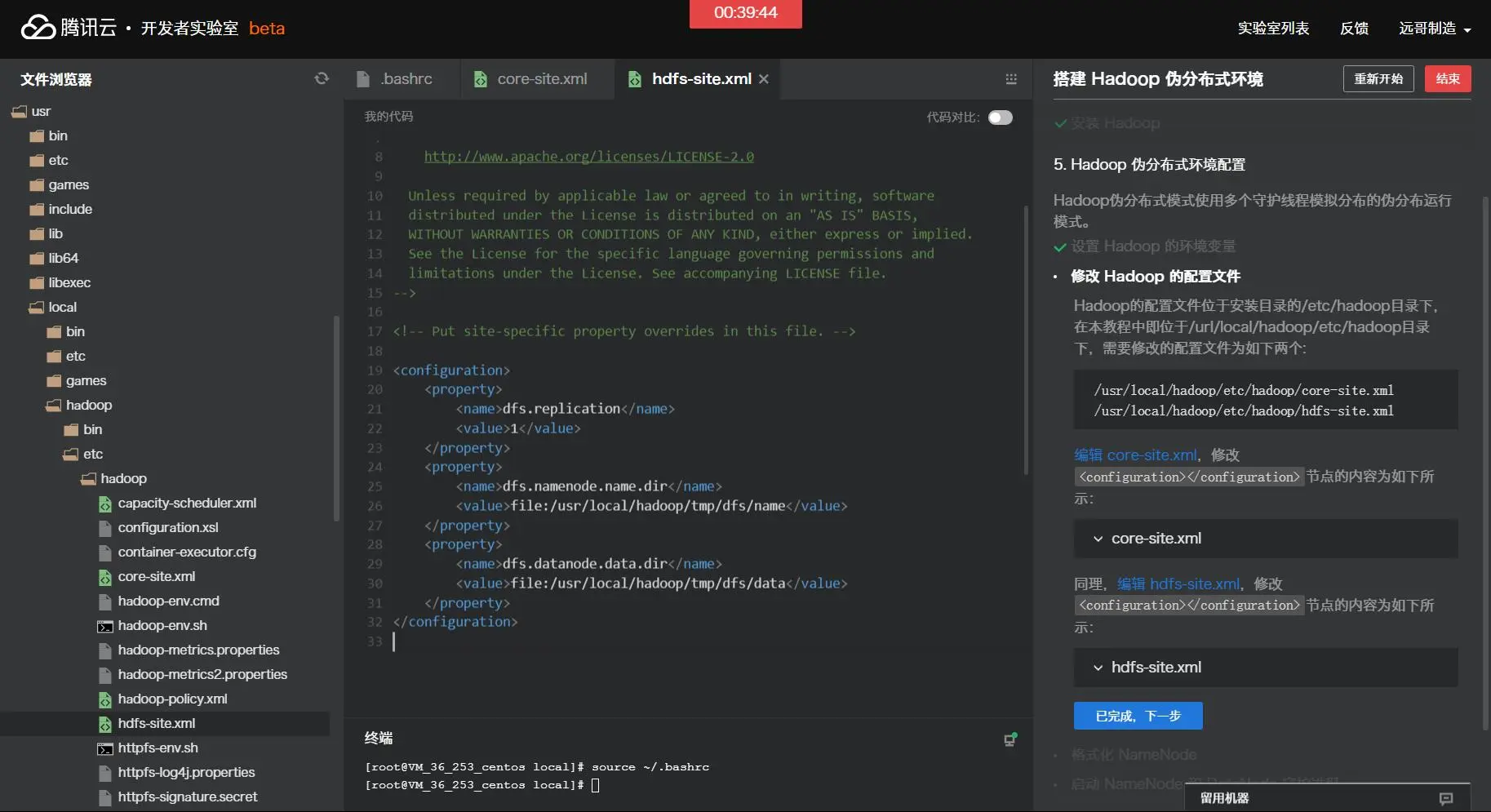
将Hadoop安装到/usr/local目录下: tar -zxf hadoop-2.7.1.tar.gz -C /usr/local 对安装的目录进行重命名,便于后续操作方便: cd /usr/local mv ./hadoop-2.7.1/ ./hadoop 检查Hadoop是否已经正确安装: /usr/local/hadoop/bin/hadoop version 如果成功输出hadoop的版本信息,表明hadoop已经成功安装。
1 2 3 4 5 6 7
[root@VM_36_253_centos local]# /usr/local/hadoop/bin/hadoop version Hadoop 2.7.1 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a Compiled by jenkins on 2015-06-29T06:04Z Compiled with protoc 2.5.0 From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.1.jar
[root@VM_36_253_centos local]# /usr/local/hadoop/sbin/start-dfs.sh 17/08/22 16:11:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for y our platform... using builtin-java classes where applicable Starting namenodes on [localhost] root@localhost's password:localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-VM_ 36_253_centos.outroot@localhost's password: localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-VM_36_253_centos.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is 22:49:b2:5c:7c:8f:73:56:89:29:8a:bd:56:49:74:66. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. root@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-VM_36_253_centos.out 17/08/22 16:11:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for y our platform... using builtin-java classes where applicable [root@VM_36_253_centos local]# jps 3355 SecondaryNameNode 3472 Jps 3051 NameNode 3191 DataNode
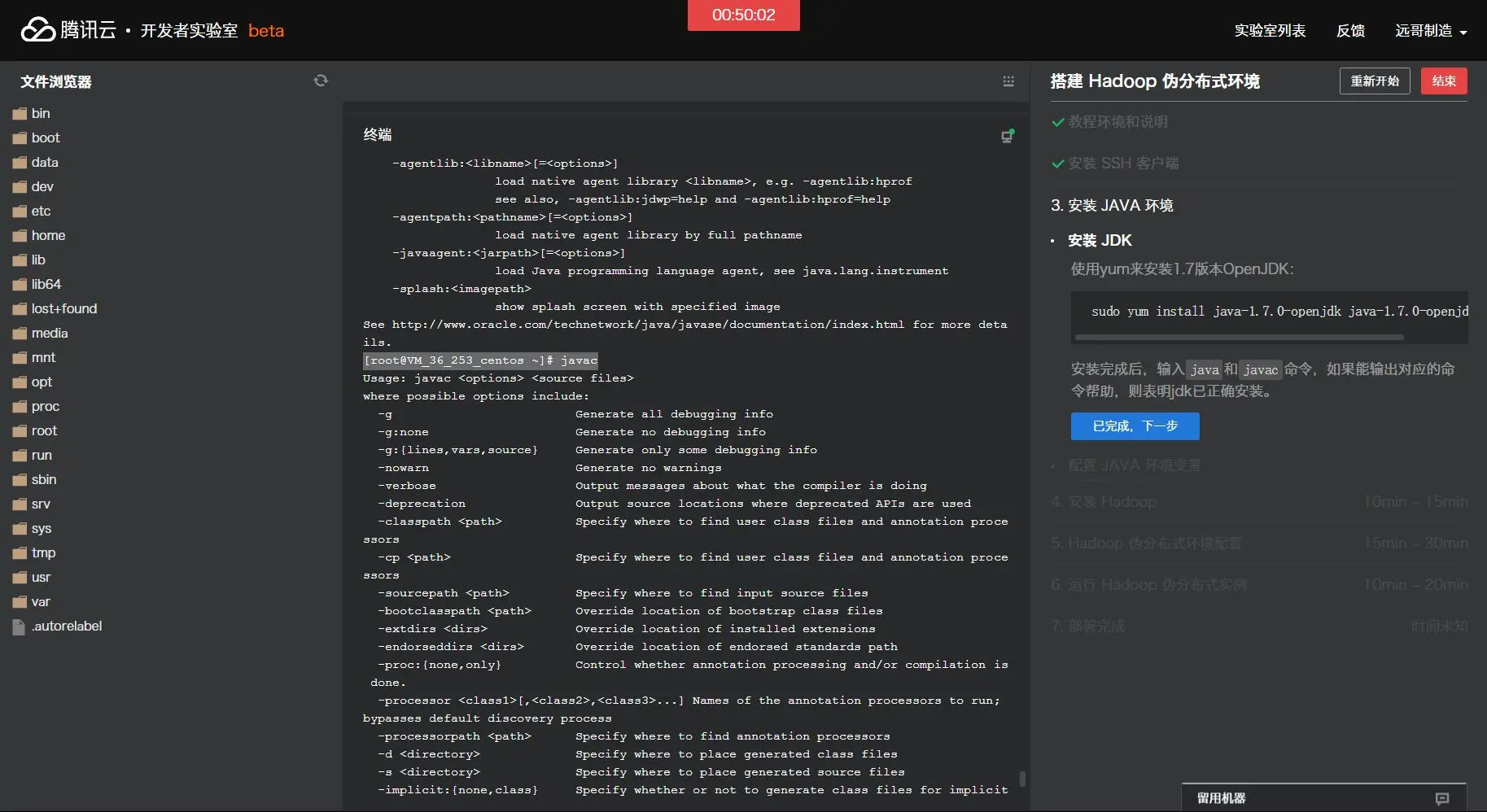
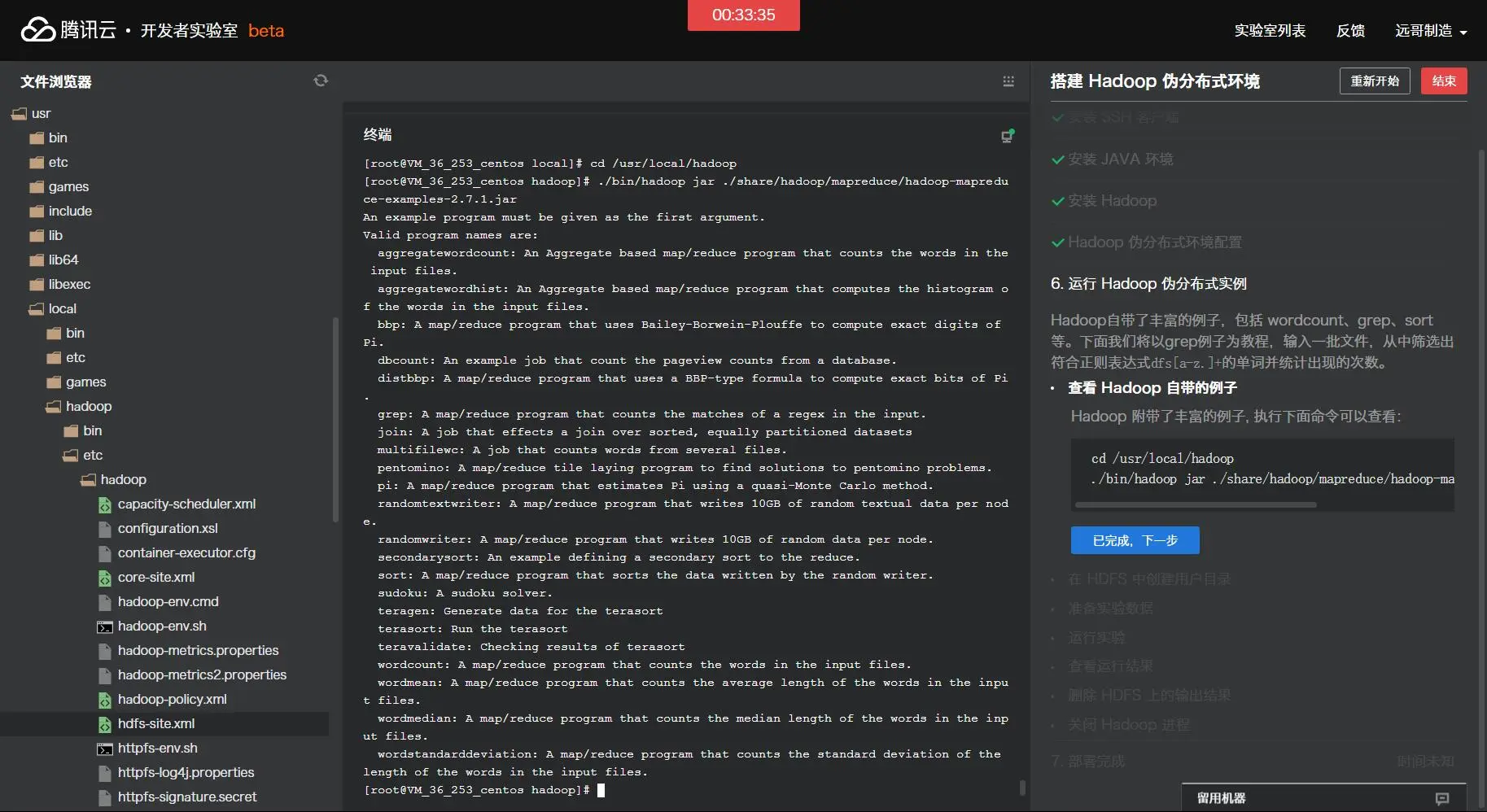
An example program must be given as the first argument. Valid program names are: aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files. aggregatewordhist: An Aggregate based map/reduce program that computes the histogram o f the words in the input files. bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi. dbcount: An example job that count the pageview counts from a database. distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi. grep: A map/reduce program that counts the matches of a regex in the input. join: A job that effects a join over sorted, equally partitioned datasets multifilewc: A job that counts words from several files. pentomino: A map/reduce tile laying program to find solutions to pentomino problems. pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method. randomtextwriter: A map/reduce program that writes 10GB of random textual data per node. randomwriter: A map/reduce program that writes 10GB of random data per node. secondarysort: An example defining a secondary sort to the reduce. sort: A map/reduce program that sorts the data written by the random writer. sudoku: A sudoku solver. teragen: Generate data for the terasort terasort: Run the terasort teravalidate: Checking results of terasort wordcount: A map/reduce program that counts the words in the input files. wordmean: A map/reduce program that counts the average length of the words in the input files. wordmedian: A map/reduce program that counts the median length of the words in the input files. wordstandarddeviation: A map/reduce program that counts the standard deviation of thelength of the words in the input files.
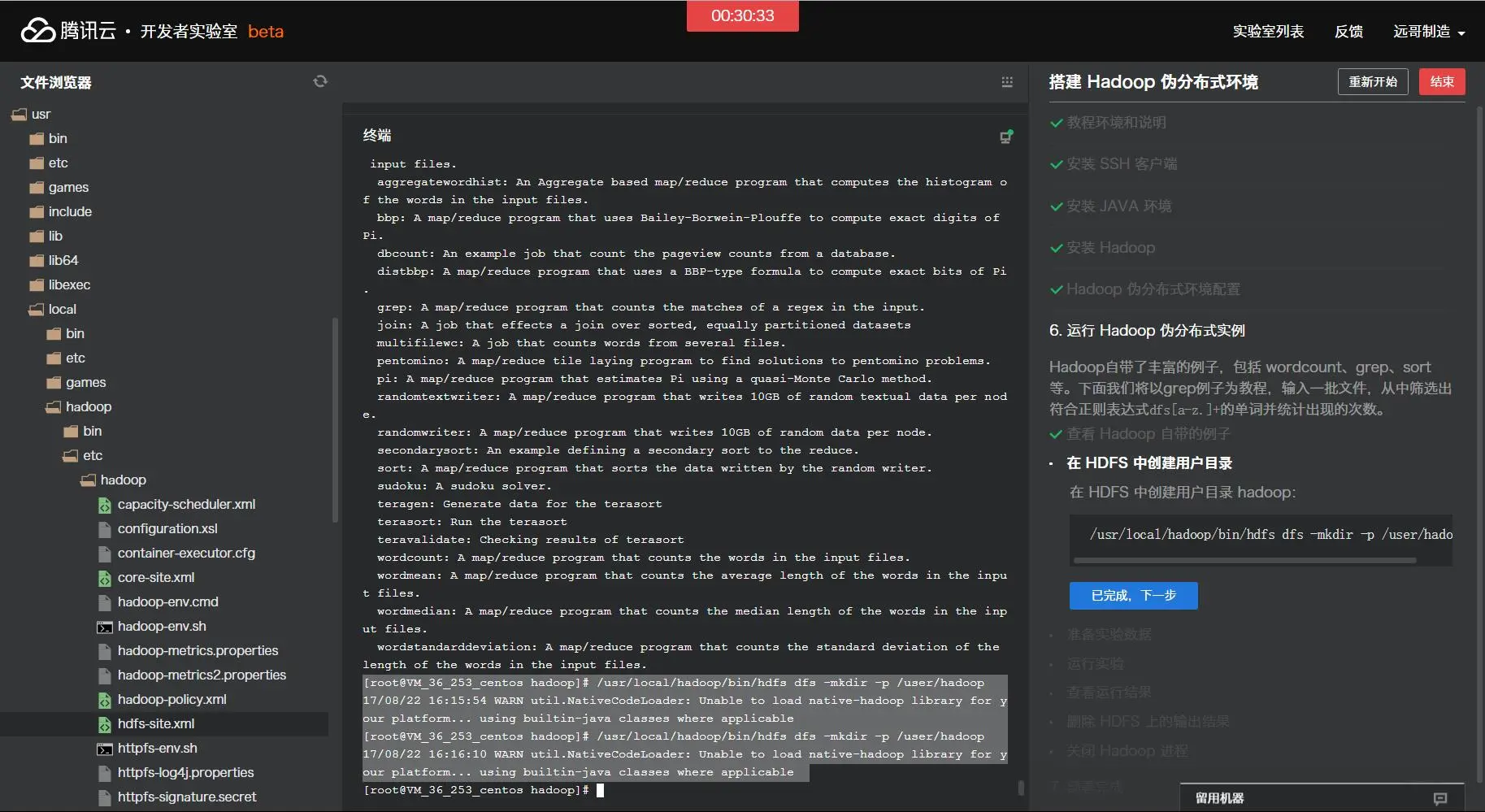
[root@VM_36_253_centos hadoop]# /usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop 17/08/22 16:15:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@VM_36_253_centos hadoop]# /usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop 17/08/22 16:16:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
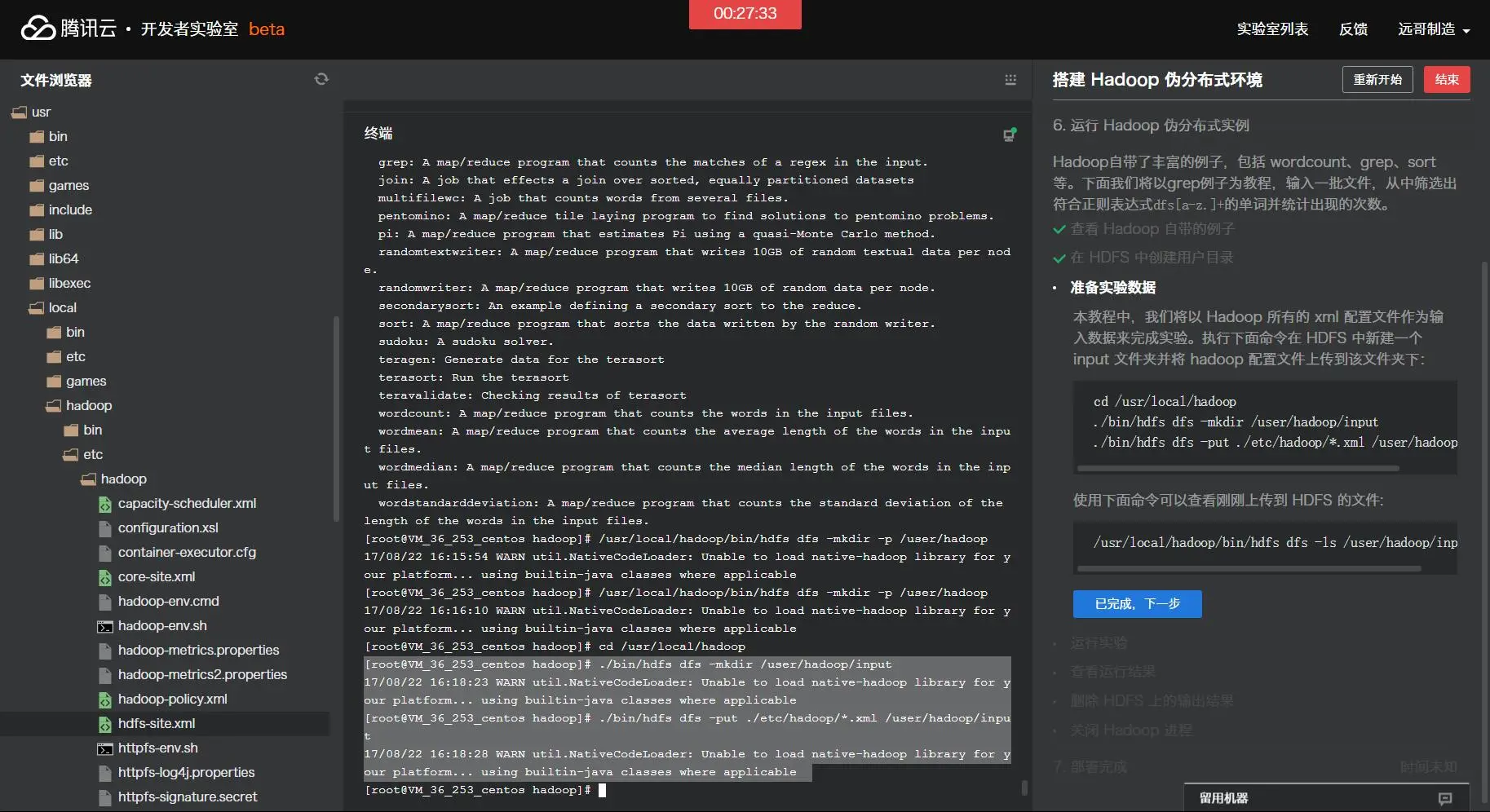
[root@VM_36_253_centos hadoop]# ./bin/hdfs dfs -mkdir /user/hadoop/input 17/08/22 16:18:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@VM_36_253_centos hadoop]# ./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input 17/08/22 16:18:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6.4 运行实验
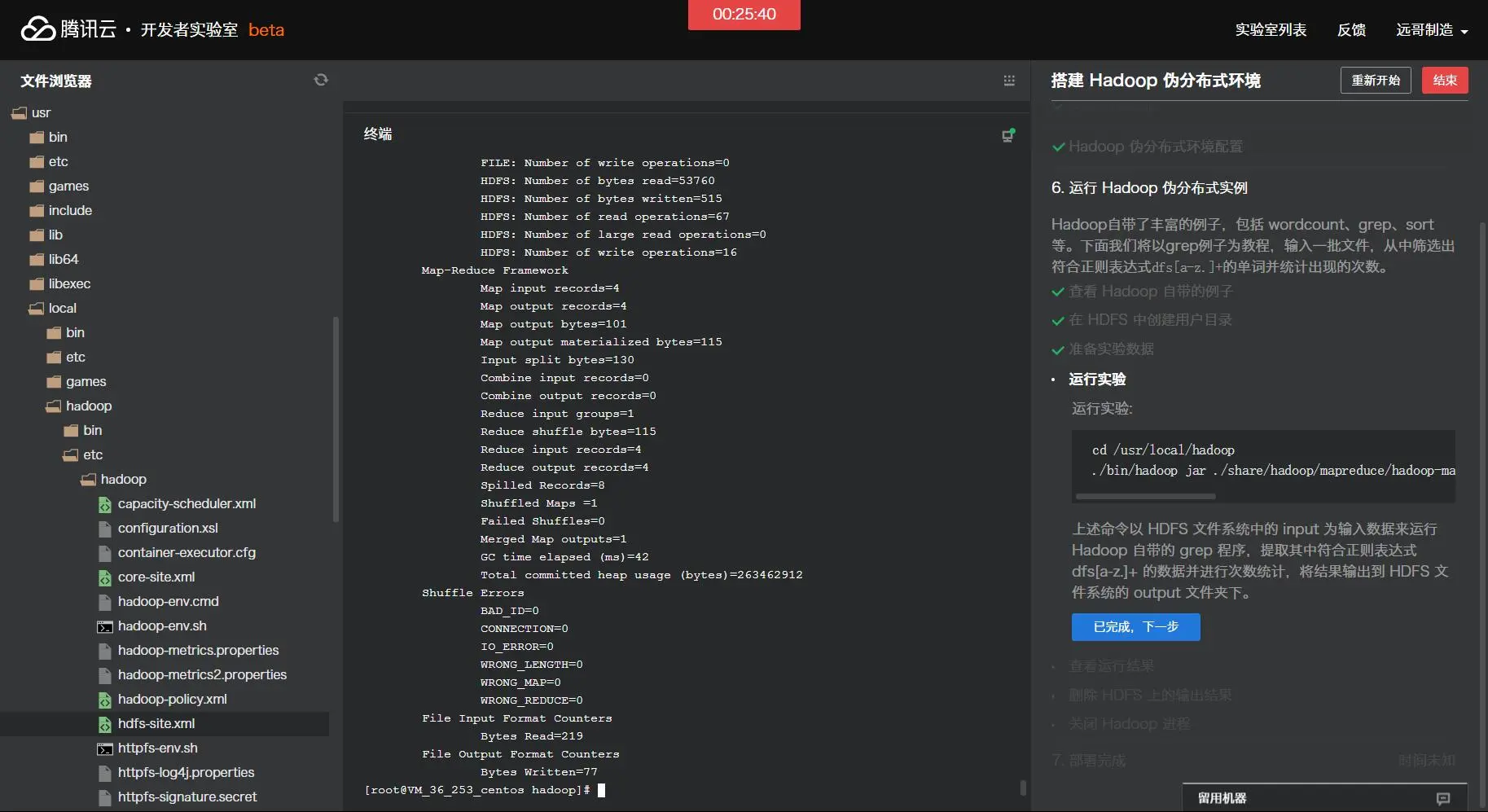
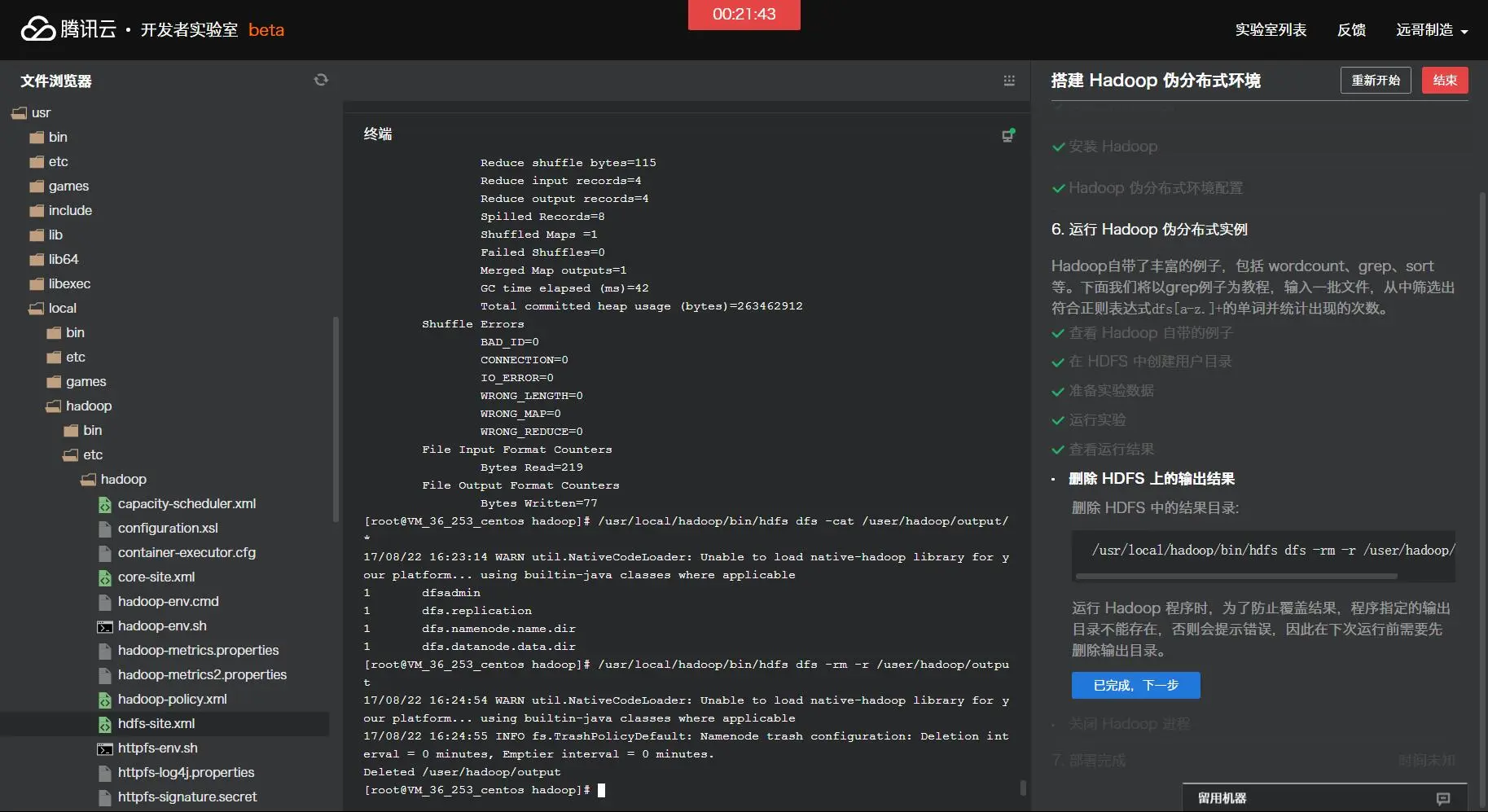
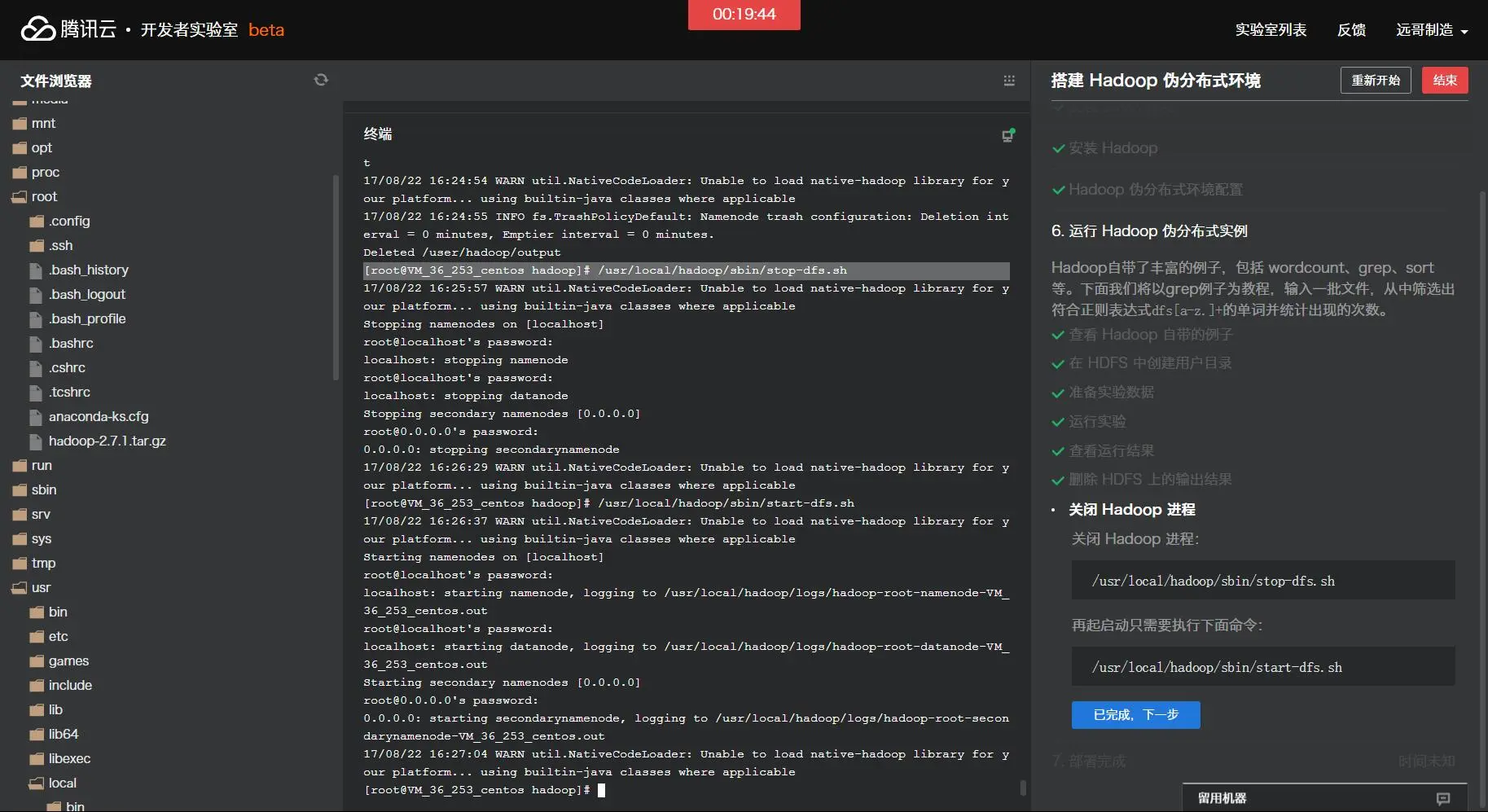
运行实验: cd /usr/local/hadoop ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+' 上述命令以HDFS文件系统中的input为输入数据来运行Hadoop自带的grep程序,提取其中符合正则表达式dfs[a-z.]+的数据并进行次数统计,将结果输出到HDFS文件系统的output文件夹下。
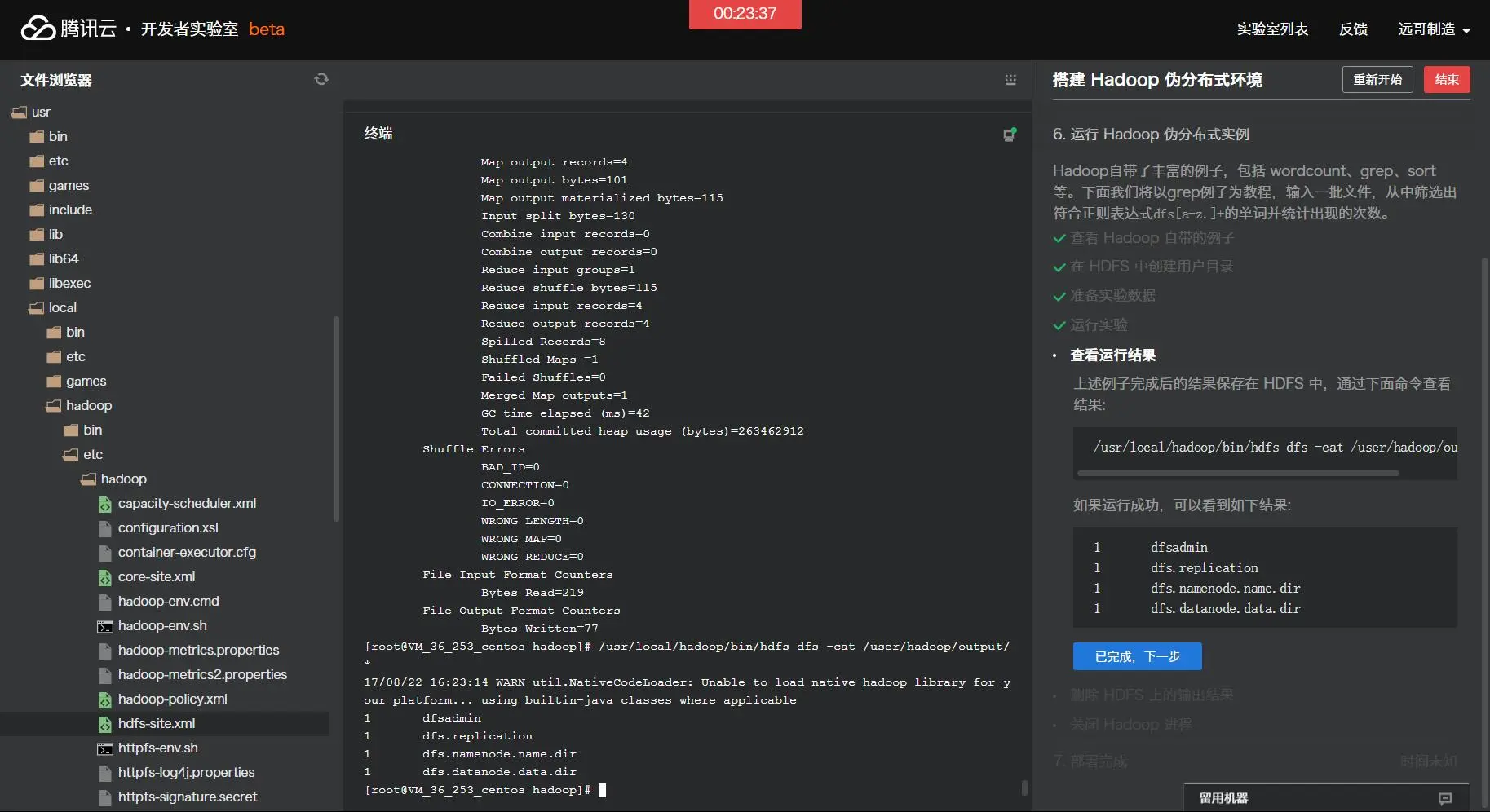
[root@VM_36_253_centos hadoop]# cd /usr/local/hadoop [root@VM_36_253_centos hadoop]# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+' 17/08/22 16:20:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/08/22 16:20:39 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 17/08/22 16:20:39 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 17/08/22 16:20:39 INFO input.FileInputFormat: Total input paths to process : 8 17/08/22 16:20:39 INFO mapreduce.JobSubmitter: number of splits:8 17/08/22 16:20:40 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local598548963_0001 17/08/22 16:20:41 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 17/08/22 16:20:41 INFO mapreduce.Job: Running job: job_local598548963_0001 17/08/22 16:20:41 INFO mapred.LocalJobRunner: OutputCommitter set in config null 17/08/22 16:20:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:41 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Waiting for map tasks 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000000_0 17/08/22 16:20:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:41 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:41 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/hadoop-policy.xml:0+9683 17/08/22 16:20:41 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:41 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:41 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:41 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:41 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:41 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:41 INFO mapred.LocalJobRunner: 17/08/22 16:20:41 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:41 INFO mapred.MapTask: Spilling map output 17/08/22 16:20:41 INFO mapred.MapTask: bufstart = 0; bufend = 17; bufvoid = 104857600 17/08/22 16:20:41 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214396(104857584); length = 1/6553600 17/08/22 16:20:41 INFO mapred.MapTask: Finished spill 0 17/08/22 16:20:41 INFO mapred.Task: Task:attempt_local598548963_0001_m_000000_0 is done. And is in the process of committing 17/08/22 16:20:41 INFO mapred.LocalJobRunner: map 17/08/22 16:20:41 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000000_0' done. 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000000_0 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000001_0 17/08/22 16:20:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:41 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:41 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/kms-site.xml:0+5511 17/08/22 16:20:41 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:41 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:41 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:41 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:41 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:41 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:41 INFO mapred.LocalJobRunner: 17/08/22 16:20:41 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:41 INFO mapred.Task: Task:attempt_local598548963_0001_m_000001_0 is done. And is in the process of committing 17/08/22 16:20:41 INFO mapred.LocalJobRunner: map 17/08/22 16:20:41 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000001_0' done. 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000001_0 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000002_0 17/08/22 16:20:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:41 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:41 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/capacity-scheduler.xml:0+4436 17/08/22 16:20:41 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:41 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:41 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:41 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:41 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:41 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:41 INFO mapred.LocalJobRunner: 17/08/22 16:20:41 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:41 INFO mapred.Task: Task:attempt_local598548963_0001_m_000002_0 is done. And is in the process of committing 17/08/22 16:20:41 INFO mapred.LocalJobRunner: map 17/08/22 16:20:41 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000002_0' done. 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000002_0 17/08/22 16:20:41 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000003_0 17/08/22 16:20:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:41 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:41 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/kms-acls.xml:0+3518 17/08/22 16:20:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:42 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 17/08/22 16:20:42 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_m_000003_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000003_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000003_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000004_0 17/08/22 16:20:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:42 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/hdfs-site.xml:0+1133 17/08/22 16:20:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:42 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 17/08/22 16:20:42 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:42 INFO mapred.MapTask: Spilling map output 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufend = 84; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214388(104857552); length = 9/6553600 17/08/22 16:20:42 INFO mapred.MapTask: Finished spill 0 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_m_000004_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000004_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000004_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000005_0 17/08/22 16:20:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:42 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/core-site.xml:0+1070 17/08/22 16:20:42 INFO mapreduce.Job: Job job_local598548963_0001 running in uber mode : false 17/08/22 16:20:42 INFO mapreduce.Job: map 100% reduce 0% 17/08/22 16:20:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:42 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 17/08/22 16:20:42 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_m_000005_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000005_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000005_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000006_0 17/08/22 16:20:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:42 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/yarn-site.xml:0+690 17/08/22 16:20:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:42 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 17/08/22 16:20:42 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_m_000006_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000006_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000006_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_m_000007_0 17/08/22 16:20:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:42 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/hadoop/input/httpfs-site.xml:0+620 17/08/22 16:20:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:42 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 17/08/22 16:20:42 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_m_000007_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_m_000007_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_m_000007_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: map task executor complete. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Waiting for reduce tasks 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Starting task: attempt_local598548963_0001_r_000000_0 17/08/22 16:20:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:42 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@4d998798 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=10 17/08/22 16:20:42 INFO reduce.EventFetcher: attempt_local598548963_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000001_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000001_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->2 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000002_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000002_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 2, commitMemory -> 2, usedMemory ->4 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000005_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000005_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 3, commitMemory -> 4, usedMemory ->6 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000003_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000003_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 4, commitMemory -> 6, usedMemory ->8 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000006_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000006_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 5, commitMemory -> 8, usedMemory ->10 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000000_0 decomp: 21 len: 25 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 21 bytes from map-output for attempt_local598548963_0001_m_000000_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 21, inMemoryMapOutputs.size() -> 6, commitMemory -> 10, usedMemory ->31 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000007_0 decomp: 2 len: 6 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local598548963_0001_m_000007_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 7, commitMemory -> 31, usedMemory ->33 17/08/22 16:20:42 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local598548963_0001_m_000004_0 decomp: 92 len: 96 to MEMORY 17/08/22 16:20:42 INFO reduce.InMemoryMapOutput: Read 92 bytes from map-output for attempt_local598548963_0001_m_000004_0 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 92, inMemoryMapOutputs.size() -> 8, commitMemory -> 33, usedMemory ->125 17/08/22 16:20:42 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 8 / 8 copied. 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: finalMerge called with 8 in-memory map-outputs and 0 on-disk map-outputs 17/08/22 16:20:42 INFO mapred.Merger: Merging 8 sorted segments 17/08/22 16:20:42 INFO mapred.Merger: Down to the last merge-pass, with 2 segments leftof total size: 78 bytes 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: Merged 8 segments, 125 bytes to disk tosatisfy reduce memory limit 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: Merging 1 files, 115 bytes from disk 17/08/22 16:20:42 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memoryinto reduce 17/08/22 16:20:42 INFO mapred.Merger: Merging 1 sorted segments 17/08/22 16:20:42 INFO mapred.Merger: Down to the last merge-pass, with 1 segments leftof total size: 87 bytes 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 8 / 8 copied. 17/08/22 16:20:42 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 17/08/22 16:20:42 INFO mapred.Task: Task:attempt_local598548963_0001_r_000000_0 is done. And is in the process of committing 17/08/22 16:20:42 INFO mapred.LocalJobRunner: 8 / 8 copied. 17/08/22 16:20:42 INFO mapred.Task: Task attempt_local598548963_0001_r_000000_0 is allowed to commit now 17/08/22 16:20:42 INFO output.FileOutputCommitter: Saved output of task 'attempt_local598548963_0001_r_000000_0' to hdfs://localhost:9000/user/root/grep-temp-1006666638/_temporary/0/task_local598548963_0001_r_000000 17/08/22 16:20:42 INFO mapred.LocalJobRunner: reduce > reduce 17/08/22 16:20:42 INFO mapred.Task: Task 'attempt_local598548963_0001_r_000000_0' done. 17/08/22 16:20:42 INFO mapred.LocalJobRunner: Finishing task: attempt_local598548963_0001_r_000000_0 17/08/22 16:20:42 INFO mapred.LocalJobRunner: reduce task executor complete. 17/08/22 16:20:43 INFO mapreduce.Job: map 100% reduce 100% 17/08/22 16:20:43 INFO mapreduce.Job: Job job_local598548963_0001 completed successfully 17/08/22 16:20:43 INFO mapreduce.Job: Counters: 35 File System Counters FILE: Number of bytes read=2501359 FILE: Number of bytes written=4984808 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=196650 HDFS: Number of bytes written=219 HDFS: Number of read operations=118 HDFS: Number of large read operations=0 HDFS: Number of write operations=11 Map-Reduce Framework Map input records=765 Map output records=4 Map output bytes=101 Map output materialized bytes=157 Input split bytes=957 Combine input records=4 Combine output records=4 Reduce input groups=4 Reduce shuffle bytes=157 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =8 Failed Shuffles=0 Merged Map outputs=8 GC time elapsed (ms)=318 Total committed heap usage (bytes)=1380876288 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=26661 File Output Format Counters Bytes Written=219 17/08/22 16:20:43 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized 17/08/22 16:20:43 INFO input.FileInputFormat: Total input paths to process : 1 17/08/22 16:20:43 INFO mapreduce.JobSubmitter: number of splits:1 17/08/22 16:20:43 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local992066578_0002 17/08/22 16:20:43 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 17/08/22 16:20:43 INFO mapreduce.Job: Running job: job_local992066578_0002 17/08/22 16:20:43 INFO mapred.LocalJobRunner: OutputCommitter set in config null 17/08/22 16:20:43 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:43 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Waiting for map tasks 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Starting task: attempt_local992066578_0002_m_000000_0 17/08/22 16:20:43 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:43 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/user/root/grep-temp-1006666638/part-r-00000:0+219 17/08/22 16:20:43 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 17/08/22 16:20:43 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 17/08/22 16:20:43 INFO mapred.MapTask: soft limit at 83886080 17/08/22 16:20:43 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 17/08/22 16:20:43 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 17/08/22 16:20:43 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 17/08/22 16:20:43 INFO mapred.LocalJobRunner: 17/08/22 16:20:43 INFO mapred.MapTask: Starting flush of map output 17/08/22 16:20:43 INFO mapred.MapTask: Spilling map output 17/08/22 16:20:43 INFO mapred.MapTask: bufstart = 0; bufend = 101; bufvoid = 104857600 17/08/22 16:20:43 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600 17/08/22 16:20:43 INFO mapred.MapTask: Finished spill 0 17/08/22 16:20:43 INFO mapred.Task: Task:attempt_local992066578_0002_m_000000_0 is done. And is in the process of committing 17/08/22 16:20:43 INFO mapred.LocalJobRunner: map 17/08/22 16:20:43 INFO mapred.Task: Task 'attempt_local992066578_0002_m_000000_0' done. 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Finishing task: attempt_local992066578_0002_m_000000_0 17/08/22 16:20:43 INFO mapred.LocalJobRunner: map task executor complete. 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Waiting for reduce tasks 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Starting task: attempt_local992066578_0002_r_000000_0 17/08/22 16:20:43 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 17/08/22 16:20:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 17/08/22 16:20:43 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5eeb4365 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=10 17/08/22 16:20:43 INFO reduce.EventFetcher: attempt_local992066578_0002_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 17/08/22 16:20:43 INFO reduce.LocalFetcher: localfetcher#2 about to shuffle output of map attempt_local992066578_0002_m_000000_0 decomp: 111 len: 115 to MEMORY 17/08/22 16:20:43 INFO reduce.InMemoryMapOutput: Read 111 bytes from map-output for attempt_local992066578_0002_m_000000_0 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 111, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->111 17/08/22 16:20:43 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 17/08/22 16:20:43 INFO mapred.LocalJobRunner: 1 / 1 copied. 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 17/08/22 16:20:43 INFO mapred.Merger: Merging 1 sorted segments 17/08/22 16:20:43 INFO mapred.Merger: Down to the last merge-pass, with 1 segments leftof total size: 101 bytes 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: Merged 1 segments, 111 bytes to disk tosatisfy reduce memory limit 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: Merging 1 files, 115 bytes from disk 17/08/22 16:20:43 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memoryinto reduce 17/08/22 16:20:43 INFO mapred.Merger: Merging 1 sorted segments 17/08/22 16:20:43 INFO mapred.Merger: Down to the last merge-pass, with 1 segments leftof total size: 101 bytes 17/08/22 16:20:43 INFO mapred.LocalJobRunner: 1 / 1 copied. 17/08/22 16:20:43 INFO mapred.Task: Task:attempt_local992066578_0002_r_000000_0 is done. And is in the process of committing 17/08/22 16:20:43 INFO mapred.LocalJobRunner: 1 / 1 copied. 17/08/22 16:20:43 INFO mapred.Task: Task attempt_local992066578_0002_r_000000_0 is allowed to commit now 17/08/22 16:20:43 INFO output.FileOutputCommitter: Saved output of task 'attempt_local992066578_0002_r_000000_0' to hdfs://localhost:9000/user/hadoop/output/_temporary/0/task_local992066578_0002_r_000000 17/08/22 16:20:43 INFO mapred.LocalJobRunner: reduce > reduce 17/08/22 16:20:43 INFO mapred.Task: Task 'attempt_local992066578_0002_r_000000_0' done. 17/08/22 16:20:43 INFO mapred.LocalJobRunner: Finishing task: attempt_local992066578_0002_r_000000_0 17/08/22 16:20:43 INFO mapred.LocalJobRunner: reduce task executor complete. 17/08/22 16:20:44 INFO mapreduce.Job: Job job_local992066578_0002 running in uber mode : false 17/08/22 16:20:44 INFO mapreduce.Job: map 100% reduce 100% 17/08/22 16:20:44 INFO mapreduce.Job: Job job_local992066578_0002 completed successfully 17/08/22 16:20:44 INFO mapreduce.Job: Counters: 35 File System Counters FILE: Number of bytes read=1108352 FILE: Number of bytes written=2210539 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=53760 HDFS: Number of bytes written=515 HDFS: Number of read operations=67 HDFS: Number of large read operations=0 HDFS: Number of write operations=16 Map-Reduce Framework Map input records=4 Map output records=4 Map output bytes=101 Map output materialized bytes=115 Input split bytes=130 Combine input records=0 Combine output records=0 Reduce input groups=1 Reduce shuffle bytes=115 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=42 Total committed heap usage (bytes)=263462912 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=219 File Output Format Counters Bytes Written=77